Créer une nouvelle colonne avec des valeurs plus rapidement et de manière efficace
je crée une colonne avec des valeurs incrémentielles, puis j'ajoute une chaîne de caractères au début de la colonne. Lorsqu'il est utilisé sur de grandes données, c'est très lent. S'il vous plaît suggérer un moyen plus rapide et efficace pour le même.
df['New_Column'] = np.arange(df[0])+1
df['New_Column'] = 'str' + df['New_Column'].astype(str)
Entrée
id Field Value
1 A 1
2 B 0
3 D 1
Sortie
id Field Value New_Column
1 A 1 str_1
2 B 0 str_2
3 D 1 str_3
4 réponses
je vais ajouter deux de plus dans le mix
Numpy
from numpy.core.defchararray import add
df.assign(new=add('str_', np.arange(1, len(df) + 1).astype(str)))
id Field Value new
0 1 A 1 str_1
1 2 B 0 str_2
2 3 D 1 str_3
f-string dans la compréhension
Python 3.6+
df.assign(new=[f'str_{i}' for i in range(1, len(df) + 1)])
id Field Value new
0 1 A 1 str_1
1 2 B 0 str_2
2 3 D 1 str_3
Test De Temps
Conclusions
la compréhension gagne le jour avec la performance relative à la simplicité. Remarquez, c'était la méthode proposée par cantsy. J'apprécie les upvotes (merci) mais donnons crédit où il est dû.
Cythoniser la compréhension ne semble pas aider. Ni f-chaînes.
Divakar numexp sort sur le dessus pour la performance sur les données plus grandes.
Fonctions
%load_ext Cython
%%cython
def gen_list(l, h):
return ['str_%s' % i for i in range(l, h)]
pir1 = lambda d: d.assign(new=[f'str_{i}' for i in range(1, len(d) + 1)])
pir2 = lambda d: d.assign(new=add('str_', np.arange(1, len(d) + 1).astype(str)))
cld1 = lambda d: d.assign(new=['str_%s' % i for i in range(1, len(d) + 1)])
cld2 = lambda d: d.assign(new=gen_list(1, len(d) + 1))
jez1 = lambda d: d.assign(new='str_' + pd.Series(np.arange(1, len(d) + 1), d.index).astype(str))
div1 = lambda d: d.assign(new=create_inc_pattern(prefix_str='str_', start=1, stop=len(d) + 1))
div2 = lambda d: d.assign(new=create_inc_pattern_numexpr(prefix_str='str_', start=1, stop=len(d) + 1))
Test
res = pd.DataFrame(
np.nan, [10, 30, 100, 300, 1000, 3000, 10000, 30000],
'pir1 pir2 cld1 cld2 jez1 div1 div2'.split()
)
for i in res.index:
d = pd.concat([df] * i)
for j in res.columns:
stmt = f'{j}(d)'
setp = f'from __main__ import {j}, d'
res.at[i, j] = timeit(stmt, setp, number=200)
Résultats
res.plot(loglog=True)
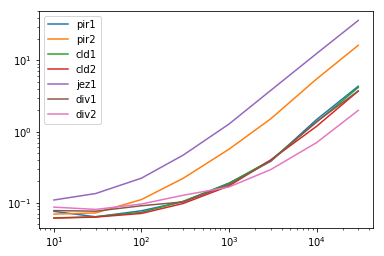
res.div(res.min(1), 0)
pir1 pir2 cld1 cld2 jez1 div1 div2
10 1.243998 1.137877 1.006501 1.000000 1.798684 1.277133 1.427025
30 1.009771 1.144892 1.012283 1.000000 2.144972 1.210803 1.283230
100 1.090170 1.567300 1.039085 1.000000 3.134154 1.281968 1.356706
300 1.061804 2.260091 1.072633 1.000000 4.792343 1.051886 1.305122
1000 1.135483 3.401408 1.120250 1.033484 7.678876 1.077430 1.000000
3000 1.310274 5.179131 1.359795 1.362273 13.006764 1.317411 1.000000
10000 2.110001 7.861251 1.942805 1.696498 17.905551 1.974627 1.000000
30000 2.188024 8.236724 2.100529 1.872661 18.416222 1.875299 1.000000
Plus De Fonctions
def create_inc_pattern(prefix_str, start, stop):
N = stop - start # count of numbers
W = int(np.ceil(np.log10(N+1))) # width of numeral part in string
dl = len(prefix_str)+W # datatype length
dt = np.uint8 # int datatype for string to-from conversion
padv = np.full(W,48,dtype=np.uint8)
a0 = np.r_[np.fromstring(prefix_str,dtype='uint8'), padv]
r = np.arange(start, stop)
addn = (r[:,None] // 10**np.arange(W-1,-1,-1))%10
a1 = np.repeat(a0[None],N,axis=0)
a1[:,len(prefix_str):] += addn.astype(dt)
a1.shape = (-1)
a2 = np.zeros((len(a1),4),dtype=dt)
a2[:,0] = a1
return np.frombuffer(a2.ravel(), dtype='U'+str(dl))
import numexpr as ne
def create_inc_pattern_numexpr(prefix_str, start, stop):
N = stop - start # count of numbers
W = int(np.ceil(np.log10(N+1))) # width of numeral part in string
dl = len(prefix_str)+W # datatype length
dt = np.uint8 # int datatype for string to-from conversion
padv = np.full(W,48,dtype=np.uint8)
a0 = np.r_[np.fromstring(prefix_str,dtype='uint8'), padv]
r = np.arange(start, stop)
r2D = r[:,None]
s = 10**np.arange(W-1,-1,-1)
addn = ne.evaluate('(r2D/s)%10')
a1 = np.repeat(a0[None],N,axis=0)
a1[:,len(prefix_str):] += addn.astype(dt)
a1.shape = (-1)
a2 = np.zeros((len(a1),4),dtype=dt)
a2[:,0] = a1
return np.frombuffer(a2.ravel(), dtype='U'+str(dl))
Quand tout le reste échoue, utilisez l'élément compréhension de liste:
df['NewColumn'] = ['str_%s' %i for i in range(1, len(df) + 1)]
d'autres accélérations sont possibles si vous cythonisez votre fonction:
%load_ext Cython
%%cython
def gen_list(l, h):
return ['str_%s' %i for i in range(l, h)]
notez que ce code est exécuté sur Python3.6.0 (IPython6.2.1). Solution améliorée grâce à @hpaulj dans les commentaires.
# @jezrael's fastest solution
%%timeit
df['NewColumn'] = np.arange(len(df['a'])) + 1
df['NewColumn'] = 'str_' + df['New_Column'].map(str)
547 ms ± 13.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# in this post - no cython
%timeit df['NewColumn'] = ['str_%s'%i for i in range(n)]
409 ms ± 9.36 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# cythonized list comp
%timeit df['NewColumn'] = gen_list(1, len(df) + 1)
370 ms ± 9.23 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
approche Proposée
après avoir bricolé un peu avec la chaîne et les dtypes numériques et en tirant parti de l'interopérabilité facile entre eux, voici quelque chose que j'ai fini par obtenir des zéros rembourrés chaînes, comme num Py fait bien et permet des opérations vectorisées de cette façon -
def create_inc_pattern(prefix_str, start, stop):
N = stop - start # count of numbers
W = int(np.ceil(np.log10(stop+1))) # width of numeral part in string
padv = np.full(W,48,dtype=np.uint8)
a0 = np.r_[np.fromstring(prefix_str,dtype='uint8'), padv]
a1 = np.repeat(a0[None],N,axis=0)
r = np.arange(start, stop)
addn = (r[:,None] // 10**np.arange(W-1,-1,-1))%10
a1[:,len(prefix_str):] += addn.astype(a1.dtype)
return a1.view('S'+str(a1.shape[1])).ravel()
Saumurage dans numexpr pour les plus rapide de radiodiffusion + modulo -
import numexpr as ne
def create_inc_pattern_numexpr(prefix_str, start, stop):
N = stop - start # count of numbers
W = int(np.ceil(np.log10(stop+1))) # width of numeral part in string
padv = np.full(W,48,dtype=np.uint8)
a0 = np.r_[np.fromstring(prefix_str,dtype='uint8'), padv]
a1 = np.repeat(a0[None],N,axis=0)
r = np.arange(start, stop)
r2D = r[:,None]
s = 10**np.arange(W-1,-1,-1)
addn = ne.evaluate('(r2D/s)%10')
a1[:,len(prefix_str):] += addn.astype(a1.dtype)
return a1.view('S'+str(a1.shape[1])).ravel()
donc, à utiliser comme nouvelle colonne:
df['New_Column'] = create_inc_pattern(prefix_str='str_', start=1, stop=len(df)+1)
essais D'échantillons -
In [334]: create_inc_pattern_numexpr(prefix_str='str_', start=1, stop=14)
Out[334]:
array(['str_01', 'str_02', 'str_03', 'str_04', 'str_05', 'str_06',
'str_07', 'str_08', 'str_09', 'str_10', 'str_11', 'str_12', 'str_13'],
dtype='|S6')
In [338]: create_inc_pattern(prefix_str='str_', start=1, stop=124)
Out[338]:
array(['str_001', 'str_002', 'str_003', 'str_004', 'str_005', 'str_006',
'str_007', 'str_008', 'str_009', 'str_010', 'str_011', 'str_012',..
'str_115', 'str_116', 'str_117', 'str_118', 'str_119', 'str_120',
'str_121', 'str_122', 'str_123'],
dtype='|S7')
Explication
idée de base et explication avec l'essai d'échantillon étape par étape
l'idée de base est de créer le tableau numérique Équivalent ASCII, qui pourrait être visualisé ou converti par conversion dtype en chaîne de caractères. Pour être plus précis, nous créerions des chiffres de type uint8. Ainsi, chaque chaîne serait représentée par un tableau 1D de chiffres. Pour la liste des chaînes qui représenterait un tableau 2D de chiffres avec chaque ligne (1D tableau) représentant une chaîne unique.
1) Entrées :
In [22]: prefix_str='str_'
...: start=15
...: stop=24
2) Paramètres:
In [23]: N = stop - start # count of numbers
...: W = int(np.ceil(np.log10(stop+1))) # width of numeral part in string
In [24]: N,W
Out[24]: (9, 2)
3) Créer un tableau 1D de chiffres représentant le départ de la chaîne :
In [25]: padv = np.full(W,48,dtype=np.uint8)
...: a0 = np.r_[np.fromstring(prefix_str,dtype='uint8'), padv]
In [27]: a0
Out[27]: array([115, 116, 114, 95, 48, 48], dtype=uint8)
4) couvrir la gamme des chaînes de caractères en tableau 2D :
In [33]: a1 = np.repeat(a0[None],N,axis=0)
...: r = np.arange(start, stop)
...: addn = (r[:,None] // 10**np.arange(W-1,-1,-1))%10
...: a1[:,len(prefix_str):] += addn.astype(a1.dtype)
In [34]: a1
Out[34]:
array([[115, 116, 114, 95, 49, 53],
[115, 116, 114, 95, 49, 54],
[115, 116, 114, 95, 49, 55],
[115, 116, 114, 95, 49, 56],
[115, 116, 114, 95, 49, 57],
[115, 116, 114, 95, 50, 48],
[115, 116, 114, 95, 50, 49],
[115, 116, 114, 95, 50, 50],
[115, 116, 114, 95, 50, 51]], dtype=uint8)
5) Ainsi, chaque ligne représente l'équivalent ascii d'une chaîne de caractères provenant de la sortie désirée. Il faut bien arriver à la dernière étape :
In [35]: a1.view('S'+str(a1.shape[1])).ravel()
Out[35]:
array(['str_15', 'str_16', 'str_17', 'str_18', 'str_19', 'str_20',
'str_21', 'str_22', 'str_23'],
dtype='|S6')
Timings
voici un test de timings rapide contre la version de compréhension de liste qui semble fonctionner le meilleur en regardant les timings d'autres messages -
In [339]: N = 10000
In [340]: %timeit ['str_%s'%i for i in range(N)]
1000 loops, best of 3: 1.12 ms per loop
In [341]: %timeit create_inc_pattern_numexpr(prefix_str='str_', start=1, stop=N)
1000 loops, best of 3: 490 µs per loop
In [342]: N = 100000
In [343]: %timeit ['str_%s'%i for i in range(N)]
100 loops, best of 3: 14 ms per loop
In [344]: %timeit create_inc_pattern_numexpr(prefix_str='str_', start=1, stop=N)
100 loops, best of 3: 4 ms per loop
codes Python-3
sur Python-3, pour obtenir le tableau string dtype, nous avons dû pad avec quelques zéros supplémentaires sur le tableau intermediate int dtype. Donc, l'équivalent sans et avec numexpr versions pour Python-3 a fini par devenir quelque chose le long de ces lignes -
Méthode n ° 1 (Pas de numexpr) :
def create_inc_pattern(prefix_str, start, stop):
N = stop - start # count of numbers
W = int(np.ceil(np.log10(stop+1))) # width of numeral part in string
dl = len(prefix_str)+W # datatype length
dt = np.uint8 # int datatype for string to-from conversion
padv = np.full(W,48,dtype=np.uint8)
a0 = np.r_[np.fromstring(prefix_str,dtype='uint8'), padv]
r = np.arange(start, stop)
addn = (r[:,None] // 10**np.arange(W-1,-1,-1))%10
a1 = np.repeat(a0[None],N,axis=0)
a1[:,len(prefix_str):] += addn.astype(dt)
a1.shape = (-1)
a2 = np.zeros((len(a1),4),dtype=dt)
a2[:,0] = a1
return np.frombuffer(a2.ravel(), dtype='U'+str(dl))
Méthode #2 (Avec numexpr) :
import numexpr as ne
def create_inc_pattern_numexpr(prefix_str, start, stop):
N = stop - start # count of numbers
W = int(np.ceil(np.log10(stop+1))) # width of numeral part in string
dl = len(prefix_str)+W # datatype length
dt = np.uint8 # int datatype for string to-from conversion
padv = np.full(W,48,dtype=np.uint8)
a0 = np.r_[np.fromstring(prefix_str,dtype='uint8'), padv]
r = np.arange(start, stop)
r2D = r[:,None]
s = 10**np.arange(W-1,-1,-1)
addn = ne.evaluate('(r2D/s)%10')
a1 = np.repeat(a0[None],N,axis=0)
a1[:,len(prefix_str):] += addn.astype(dt)
a1.shape = (-1)
a2 = np.zeros((len(a1),4),dtype=dt)
a2[:,0] = a1
return np.frombuffer(a2.ravel(), dtype='U'+str(dl))
Horaires...
In [8]: N = 100000
In [9]: %timeit ['str_%s'%i for i in range(N)]
100 loops, best of 3: 18.5 ms per loop
In [10]: %timeit create_inc_pattern_numexpr(prefix_str='str_', start=1, stop=N)
100 loops, best of 3: 6.06 ms per loop
une solution possible est de convertir les valeurs en strings par map:
df['New_Column'] = np.arange(len(df['a']))+1
df['New_Column'] = 'str_' + df['New_Column'].map(str)