Créer une table à partir des résultats de recherche dans Google BigQuery
nous utilisons Google BigQuery via L'API Python. Comment puis-je créer une table (nouvelle ou remplacer une ancienne) à partir des résultats de la requête? J'ai examiné l' documentation d'interrogation, mais je n'ai pas trouvé cela utile.
Nous voulons simuler:
" SELEC ... DANS. .."à partir de la norme ANSI SQL.
3 réponses
Vous pouvez le faire en spécifiant une table de destination de la requête. Vous devez utiliser le Jobs.insert API plutôt que le Jobs.query appel, et vous devez spécifier writeDisposition=WRITE_APPEND et remplissez la table de destination.
voici à quoi ressemblerait la configuration si vous utilisiez l'API brute. Si vous utilisez Python, Le client Python devrait donner accès à ces mêmes champs:
"configuration": {
"query": {
"query": "select count(*) from foo.bar",
"destinationTable": {
"projectId": "my_project",
"datasetId": "my_dataset",
"tableId": "my_table"
},
"createDisposition": "CREATE_IF_NEEDED",
"writeDisposition": "WRITE_APPEND",
}
}
la réponse acceptée est correcte, mais elle ne fournit pas de code Python pour effectuer la tâche. Voici un exemple, refactorisé d'une petite classe de client personnalisé que je viens d'écrire. Il ne traite pas les exceptions, et la requête codée en dur devrait être personnalisée pour faire quelque chose de plus intéressant que juste SELECT * ...
import time
from google.cloud import bigquery
from google.cloud.bigquery.table import Table
from google.cloud.bigquery.dataset import Dataset
class Client(object):
def __init__(self, origin_project, origin_dataset, origin_table,
destination_dataset, destination_table):
"""
A Client that performs a hardcoded SELECT and INSERTS the results in a
user-specified location.
All init args are strings. Note that the destination project is the
default project from your Google Cloud configuration.
"""
self.project = origin_project
self.dataset = origin_dataset
self.table = origin_table
self.dest_dataset = destination_dataset
self.dest_table_name = destination_table
self.client = bigquery.Client()
def run(self):
query = ("SELECT * FROM `{project}.{dataset}.{table}`;".format(
project=self.project, dataset=self.dataset, table=self.table))
job_config = bigquery.QueryJobConfig()
# Set configuration.query.destinationTable
destination_dataset = self.client.dataset(self.dest_dataset)
destination_table = destination_dataset.table(self.dest_table_name)
job_config.destination = destination_table
# Set configuration.query.createDisposition
job_config.create_disposition = 'CREATE_IF_NEEDED'
# Set configuration.query.writeDisposition
job_config.write_disposition = 'WRITE_APPEND'
# Start the query
job = self.client.query(query, job_config=job_config)
# Wait for the query to finish
job.result()
créer une table à partir des résultats de la requête dans Google BigQuery. En supposant que vous utilisez Jupyter Notebook avec Python 3 va expliquer les étapes suivantes:
- comment créer un nouvel ensemble de données sur BQ (pour sauvegarder les résultats)
- comment exécuter une requête et enregistrer les résultats dans un nouvel ensemble de données au format de table sur BQ
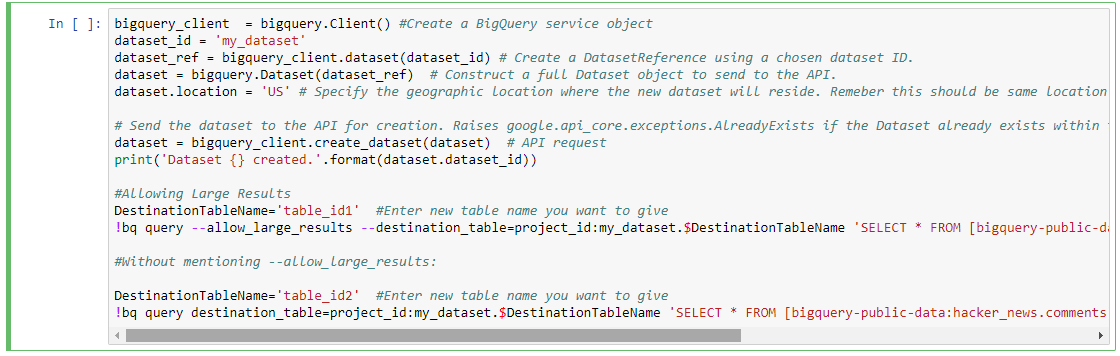
créer un nouvel ensemble de données sur BQ: my_dataset
bigquery_client = bigquery.Client() #Create a BigQuery service object
dataset_id = 'my_dataset'
dataset_ref = bigquery_client.dataset(dataset_id) # Create a DatasetReference using a chosen dataset ID.
dataset = bigquery.Dataset(dataset_ref) # Construct a full Dataset object to send to the API.
dataset.location = 'US' # Specify the geographic location where the new dataset will reside. Remember this should be same location as that of source data set from where we are getting data to run a query
# Send the dataset to the API for creation. Raises google.api_core.exceptions.AlreadyExists if the Dataset already exists within the project.
dataset = bigquery_client.create_dataset(dataset) # API request
print('Dataset {} created.'.format(dataset.dataset_id))
lancer une requête sur BQ en utilisant Python:
il y a 2 types ici:
- Permettant De Grands Résultats
- interrogation sans mention de grand résultat etc.
je suis de prendre le Public dataset ici: bigquery-public-données:hacker_news & Table id: commentaires pour exécuter une requête.
Permettant De Grands Résultats
DestinationTableName='table_id1' #Enter new table name you want to give
!bq query --allow_large_results --destination_table=project_id:my_dataset.$DestinationTableName 'SELECT * FROM [bigquery-public-data:hacker_news.comments]'
cette requête permettra d'obtenir des résultats plus importants si nécessaire.
Sans mentionner --allow_large_results:
DestinationTableName='table_id2' #Enter new table name you want to give
!bq query destination_table=project_id:my_dataset.$DestinationTableName 'SELECT * FROM [bigquery-public-data:hacker_news.comments] LIMIT 100'
Cela fonctionne pour la requête où le résultat ne va pas dépasser la limite mentionnée dans la documentation Google BQ.
Sortie:
- un nouvel ensemble de données sur BQ avec le nom my_dataset
- Résultats des requêtes enregistrées sous forme de tableaux dans my_dataset
Remarque:
- Ces requêtes sont des Commandes que vous pouvez exécuter sur le terminal(sans ! dans le début). Mais comme nous utilisons Python pour exécuter ces commandes / requêtes que nous utilisons !. Ce nous permettra d'utiliser/d'exécuter des commandes dans le programme Python.
- veuillez également noter la réponse:). remercier.