Réseau neuronal convolutionnel (CNN) pour L'Audio
j'ai suivi les tutoriels sur DeepLearning.net apprendre à mettre en place un réseau neuronal convolutionnel qui extrait les traits des images. Le tutoriel bien expliqué, facile à comprendre et à suivre.
je veux étendre la même CNN pour extraire les fonctionnalités multimodales des vidéos (images + audio) en même temps.
je comprends que l'entrée vidéo n'est rien mais une séquence d'images (des intensités de pixels) est affiché dans une période de temps (ex. 30 FPS) associée avec de l'audio. Cependant, je ne comprends pas vraiment ce qu'est l'audio, comment il fonctionne, ou comment il est décomposé pour être alimenté dans le réseau.
j'ai lu quelques articles sur le sujet (multi-modale de l'extraction de caractéristiques/représentation), mais personne n'a expliqué comment audio d'inscription au réseau.
en outre, je comprends de mes études que la représentation multimodalité est la façon dont notre cerveau fonctionne vraiment, car nous ne filtrons pas délibérément nos sens pour atteindre compréhension. Tout se passe simultanément sans que nous le sachions (représentation conjointe). Un exemple simple serait, si nous entendons un rugissement de lion, nous composons instantanément une image mentale d'un lion, nous sentons le danger et vice-versa. Plusieurs modèles neurones sont activés dans notre cerveau pour parvenir à une compréhension globale de ce qu'est un lion ressemble à, ressemble, se sent comme, sent, etc.
Le ci-dessus mentionné, c'est mon but ultime, mais pour le moment je suis tomber mon problème par souci de simplicité.
j'apprécierais vraiment que quelqu'un puisse nous éclairer sur la façon dont l'audio est disséqué et ensuite représenté dans un réseau neuronal convolutionnel. J'apprécierais également vos réflexions en ce qui concerne la synchronisation multimodale, les représentations conjointes, et quelle est la bonne façon de former une CNN avec des données multimodales.
EDIT: J'ai trouvé le son peut être représenté comme spectrogrammes. Comme un format commun pour les audio et est représenté comme un graphe à deux dimensions géométriques où la ligne horizontale représente le temps et l'ordonnée représente la fréquence.
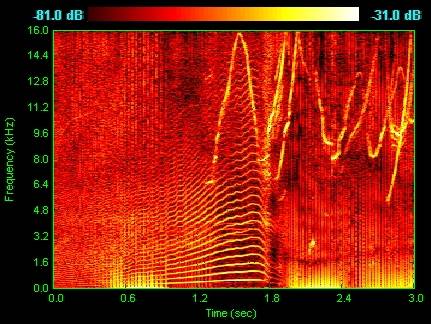
Est-il possible d'utiliser la même technique avec des images sur ces spectrogrammes? En d'autres termes, puis-je simplement utiliser ces spectrogrammes comme images d'entrée pour mon réseau neuronal convolutionnel?
2 réponses
nous avons utilisé des réseaux convolutionnels profonds sur des spectrogrammes pour une tâche d'identification de la langue parlée. Nous avions une précision d'environ 95% sur un ensemble de données fourni en ce concours de TopCoder. Les détails sont ici.
les réseaux convolutionnels simples ne saisissent pas les caractéristiques temporelles, donc par exemple dans ce travail la sortie du réseau convolutionnel a été transmise à un réseau neuronal à retardement. Mais nos expériences montrent que, même sans éléments supplémentaires les réseaux convolutionnels peuvent bien fonctionner au moins sur certaines tâches lorsque les entrées ont des tailles similaires.
il existe de nombreuses techniques pour extraire les vecteurs de fonctionnalités à partir de données audio afin de former les classificateurs. Le plus couramment utilisé est appelé MFCC (Mel-frequency cepstrum), que vous pouvez considérer comme un spectrogramme "amélioré", en conservant des informations plus pertinentes pour distinguer entre les classes. Une autre technique couramment utilisée est le PLP (Perceptual Linear Predictive Predictive), qui donne également de bons résultats. Ce sont encore beaucoup d'autres moins connus.
Plus récemment profonde réseaux ont été utilisés pour extract dispose de vecteurs par eux-mêmes, donc de façon plus similaire à la façon dont nous le faisons dans la reconnaissance d'image. C'est un domaine de recherche actif. Il n'y a pas longtemps, nous avons également utilisé des extracteurs de fonction pour former des classificateurs d'images (SIFT, HOG, etc.), mais ceux-ci ont été remplacés par des techniques d'apprentissage en profondeur, qui ont des images brutes comme entrées et des vecteurs de fonctions d'extraction par eux-mêmes (en fait, c'est ce que l'apprentissage en profondeur est vraiment).
Il est également très important de noter que les données audio sont séquentiels. Après formation d'un classificateur vous devez former un modèle séquentiel comme un HMM ou CRF, qui choisit les séquences les plus probables d'unités de parole, en utilisant comme entrée les probabilités données par votre Classificateur.
un bon point de départ pour apprendre la reconnaissance de la parole est Jursky et Martins: traitement de la parole et du langage. Il explique très bien tous ces concepts.
[ EDIT: ajouter des informations pouvant s'avérer utiles]
Il y a beaucoup de discours toolkits de reconnaissance avec des modules pour extraire des vecteurs de fonctionnalités MFCC à partir de fichiers audio, mais l'utilisation que dans ce but n'est pas toujours simple. Je suis actuellement à l'aide de CMU Sphinx4. Il a une classe appelée FeatureFileDumper, qui peut être utilisé seul pour générer des vecteurs MFCC à partir de fichiers audio.