Compiler une application pour une utilisation dans des environnements hautement radioactifs
nous compilons une application C/C++ intégrée qui est déployée dans un dispositif blindé dans un environnement bombardé de rayonnements ionisants . Nous utilisons GCC et la compilation croisée pour ARM. Lorsqu'elle est déployée, notre application génère des données erronées et se bloque plus souvent que nous le souhaiterions. Le matériel est conçu pour cet environnement, et notre application fonctionne sur cette plateforme depuis plusieurs années.
y a-t-il des changements que nous pouvons faire à notre code, ou des améliorations du temps de compilation qui peuvent être faites pour identifier/corriger les erreurs et la corruption de la mémoire causée par les perturbations d'événement simple ? D'autres développeurs ont-ils réussi à réduire les effets néfastes des erreurs soft sur une application de longue durée?
23 réponses
travaillant pendant environ 4-5 ans avec le développement de logiciels/microprogrammes et les essais d'environnement de satellites miniaturisés *, je voudrais partager mon expérience ici.
* ( les satellites miniaturisés sont beaucoup plus enclins à un événement unique que les satellites plus gros en raison de ses dimensions relativement petites et limitées pour ses composants électroniques )
pour être très concis et direct: il n'est pas un mécanisme pour récupérer de détectable, erroné situation par le logiciel/firmware lui-même sans , au moins, un copie de minimum "version de travail 151960920" du logiciel/firmware quelque part pour récupération - et avec le matériel prenant en charge la récupération de (fonctionnelle).
Maintenant, cette situation est normalement traitée à la fois au niveau du matériel et du logiciel. Ici, comme vous le demande, je vais partager ce que nous pouvons faire au niveau logiciel.
-
...récupération de but... . Fournir la capacité de mettre à jour/recompiler/reformater votre logiciel/micrologiciel dans l'environnement réel. Il s'agit d'une caractéristique presque indispensable pour tout logiciel/microprogramme dans un environnement fortement ionisé. Sans cela, vous pourrait avoir des logiciels/matériels redondants autant que vous voulez mais à un moment, ils vont tous exploser. Alors, préparez cette fonctionnalité!
-
...version de travail minimale... ont responsive, multiple copies, version minimale du logiciel/microprogramme dans votre code. C'est comme le mode de sécurité dans les fenêtres. Au lieu d'avoir une seule version entièrement fonctionnelle de votre logiciel, ayez plusieurs copies de la version minimale de votre logiciel / micrologiciel. La copie minimum aura généralement beaucoup moins de taille que la copie complète et presque toujours avoir seulement les deux ou trois caractéristiques suivantes:
- capable d'écouter, de commande à partir d'un système externe,
- permettant la mise à jour du logiciel/firmware,
- capable de surveiller les données d'entretien de l'opération de base.
-
...copie... quelque part... ont un logiciel/microprogramme redondant quelque part.
-
vous pouvez, avec ou sans matériel redondant, essayer d'avoir un logiciel/microprogramme redondant dans votre bras uC. Ceci est normalement fait en ayant deux ou plusieurs logiciels/firmware identiques dans des adresses séparées qui envoient heartbeat l'un à l'autre - mais seulement un sera actif à la fois. Si un ou plusieurs logiciels/microprogrammes ne répondent pas, passez à l'autre. L'avantage d'utiliser cette approche est que nous pouvons avoir un remplacement fonctionnel immédiatement après qu'une erreur se produit - sans aucun contact avec quelque Système/partie externe que ce soit qui est responsable de détecter et de réparer l'erreur (dans le cas d'un satellite, il s'agit habituellement du Centre de contrôle de Mission (ccm)).
à proprement parler, sans matériel redondant, le l'inconvénient de faire cela est que vous en fait ne peut pas éliminer tout point unique des échecs. À tout le moins, vous aurez toujours un point de défaillance unique, qui est , le commutateur lui-même (ou souvent le début du code). Néanmoins, pour un dispositif limité par sa taille dans un environnement fortement ionisé( comme les satellites pico / femto), la réduction du point unique de défaillance à un point sans matériel supplémentaire sera toujours à considérer. Somemore, le morceau de code pour la commutation serait certainement beaucoup moins que le code pour l'ensemble du programme de réduire considérablement le risque de contracter un Événement Unique.
-
mais si vous ne le faites pas, vous devriez avoir au moins une copie dans votre système externe qui peut venir en contact avec l'appareil et mettre à jour le logiciel/firmware (dans le satellite il s'agit là encore du centre de contrôle de mission).
- vous pouvez également avoir la copie dans votre mémoire permanente dans votre appareil qui peut être déclenché pour restaurer le logiciel/firmware du système en cours d'exécution
-
-
...situation erronée détectable.. l'erreur doit être détectable , généralement par le matériel correction/détection d'erreur circuit ou par un petit morceau de code pour la correction/détection d'erreur. Il est préférable de mettre un tel code petit, multiple, et indépendant du logiciel principal/microprogramme. Sa tâche principale est seulement pour le contrôle / correction. Si le circuit/firmware matériel est fiable (comme il est plus de rayonnement durci que les restes - ou ayant plusieurs circuits/logics), alors vous pourriez envisager de faire erreur-correction avec elle. Mais si elle ne l'est pas, il est mieux de faire comme erreur de détection. La correction peut être effectuée par un système/dispositif externe. Pour la correction d'erreur, vous pourriez envisager d'utiliser un algorithme de correction d'erreur de base comme Hamming/Golay23, parce qu'ils peuvent être mis en œuvre plus facilement à la fois dans le circuit/logiciel. Mais cela dépend en fin de compte de la capacité de votre équipe. Pour la détection d'erreurs, normalement le CRC est utilisé.
-
...matériel supportant la récupération maintenant, vient à l'aspect le plus difficile sur cette question. Finalement, la récupération nécessite que le matériel responsable de la récupération soit au moins fonctionnel. Si le matériel est cassé en permanence (normalement après que sa dose totale d'ionisation atteint un certain niveau), alors il n'y a (malheureusement) aucun moyen pour le logiciel d'aider à la récupération. Ainsi, le matériel est à juste titre la préoccupation la plus importante pour un dispositif exposé à des le niveau de rayonnement (comme la télévision).
en plus de la suggestion d'anticiper l'erreur de firmware due à un événement contrarié, je voudrais également vous suggérer d'avoir:
-
Erreur de détection et/ou de l'algorithme de correction des erreurs dans l'inter-sous-système de protocole de communication. Il s'agit d'un autre presque doit avoir afin d'éviter incomplets/mauvais signaux reçus d'autres systèmes
-
filtre dans votre lecture ADC. Faire pas utiliser le connecteur active directory de lecture directement. Filtrer par filtre médian, filtre moyen, ou tout autre filtre - jamais confiance simple valeur de lecture. Échantillonnez plus, pas moins - raisonnablement.
la NASA a un papier sur le rayonnement trempé du logiciel. Il décrit trois tâches principales:
- surveillance régulière de la mémoire pour déceler les erreurs et les effacer, "151980920 robuste" erreur de récupération des mécanismes, et
- la possibilité de reconfigurer si quelque chose ne fonctionne plus.
notez que le taux de balayage de la mémoire doit être assez fréquent pour que les erreurs multi-bits rarement se produire, comme la plupart ECC mémoire peut récupérer des erreurs mono-bit, pas multi-bit erreurs.
récupération D'erreur robuste comprend le transfert de flux de contrôle (généralement redémarrer un processus à un point avant l'erreur), la libération de ressources, et la restauration de données.
Leur principale recommandation pour la restauration des données est d'éviter la nécessité d'avoir des données intermédiaires être traités comme temporaire, de sorte que le redémarrage avant que l'erreur renvoie également les données dans un état fiable. Cela ressemble au concept de" transactions " dans les bases de données.
ils discutent des techniques particulièrement appropriées pour les langages orientés objet tels que C++. Par exemple
- ECCs logicielles pour objets mémoire contigus
- programmation par contrat : vérification des conditions préalables et postconditions, puis Vérification de l'objet pour vérifier qu'il est encore dans un état valide.
et, il se trouve que la NASA a utilisé le C++ pour de grands projets tels que le Mars Rover .
Classe C++ l'abstraction et l'encapsulation ont permis un développement et des tests rapides parmi plusieurs projets et développeurs.
ils ont évité certaines fonctionnalités C++ qui pourraient créer des problèmes:
- Exceptions
- Modèles
- Iostream (pas de console)
- héritage Multiple
- surcharge de L'opérateur (autre que
newetdelete) - allocation dynamique (utilisé une réserve de mémoire dédiée et le placement
newpour éviter la possibilité de corruption du tas de système).
voici quelques pensées et idées:
utilisez ROM de façon plus créative.
stockez tout ce que vous pouvez dans ROM. Au lieu de calculer les choses, stocker les tables de recherche dans ROM. (Assurez-vous que votre compilateur affiche vos tables de recherche dans la section en lecture seule! Imprimez les adresses mémoire à l'exécution pour vérifier!) Stockez votre table vectorielle d'interruption dans ROM. Bien sûr, faites des tests pour voir si votre ROM est fiable par rapport à votre RAM.
utilisez votre meilleur RAM pour la pile.
seuls dans la pile sont probablement la source la plus probable des accidents, parce que c'est là que des choses comme les variables d'indice, variables d'état, adresses de retour, et des pointeurs de diverses sortes vivent typiquement.
mettre en œuvre les routines timer-tick et watchdog timer.
vous pouvez exécuter un "contrôle de santé mentale" routine chaque fois tick, ainsi qu'une routine de chien de garde pour gérer le système de fermeture. Votre code principal pourrait aussi périodiquement incrémenter un compteur pour indiquer le progrès, et la routine de vérification de la santé mentale pourrait s'assurer que cela s'est produit.
mettre en Œuvre error-correcting codes dans le logiciel.
vous pouvez ajouter de la redondance à vos données pour pouvoir détecter et/ou corriger des erreurs. Cela va ajouter du temps de traitement, laissant potentiellement le processeur exposé au rayonnement pendant une plus longue période, augmentant ainsi le risque d'erreurs, vous devez donc envisager le compromis.
souvenez-vous des caches.
vérifiez les tailles de vos caches CPU. Les données que vous avez consultées ou modifiées récemment se trouveront probablement dans un cache. Je crois que vous pouvez désactiver au moins certaines des caches (à un coût de performance Élevé); vous devriez essayer ceci pour voir à quel point les caches sont sensibles à SEUs. Si les caches sont plus robustes que RAM, vous pouvez lire et réécrire régulièrement les données critiques pour vous assurer qu'elles restent dans le cache et ramènent RAM en ligne.
utiliser habilement les manipulateurs page-fault.
si vous marquez une page mémoire comme non-présente, le CPU émettra un défaut de page lorsque vous tenterez d'y accéder. Vous pouvez créer un handler page-fault qui effectue quelques vérifications avant de traiter la requête de lecture. (Les systèmes d'exploitation de PC utilisent ceci pour chargez de manière transparente les pages qui ont été échangées sur un disque.)
utilisez un langage d'assemblage pour les choses critiques (qui pourrait être tout).
avec le langage d'assemblage, vous savez ce qui est dans les registres et ce qui est en RAM; vous savoir quelles tables de RAM spéciales le CPU utilise, et vous pouvez concevoir les choses d'une manière détournée pour garder votre risque bas.
Use objdump de vraiment regarder les générées langage d'assemblage, et le code de chacune de vos routines.
si vous utilisez un gros OS comme Linux, alors vous cherchez les ennuis; il y a tellement de complexité et tellement de choses à se tromper.
souvenez-vous que c'est un jeu de probabilités.
un commentateur a dit
chaque routine à laquelle vous écrivez les erreurs de capture seront sujettes à l'échec lui-même de la même cause.
bien que cela soit vrai, les chances d'erreurs dans les (disons) 100 octets de code et de données nécessaires pour qu'une routine de vérification fonctionne correctement sont beaucoup plus faibles que les chances d'erreurs ailleurs. Si votre ROM est assez fiable et que presque toutes les données sont en ROM, vos chances sont encore meilleures.
utiliser du matériel redondant.
utiliser 2 configurations matérielles identiques ou plus avec un code identique. Si les résultats diffèrent, une réinitialisation doit être déclenchée. Avec 3 ou plusieurs appareils, vous pouvez utiliser un "vote" pour essayer d'identifier ce qui a été compromis.
vous pourriez également être intéressé par la riche littérature sur le sujet de la tolérance algorithmique des défauts. Cela inclut l'ancienne tâche: écrire une sorte qui trie correctement son entrée quand un nombre constant de comparaisons échouera (ou, la version légèrement plus maléfique, quand le nombre asymptotique de comparaisons échoue échelles comme log(n) pour n comparaisons).
Un endroit pour commencer la lecture est Huang et d'Abraham 1984 papier " Algorithme à Base de Tolérance de défaut pour les opérations matricielles ". Leur idée est vaguement similaire au calcul chiffré homomorphique (mais ce n'est pas vraiment la même chose, car ils tentent la détection/correction d'erreur au niveau de l'opération).
un descendant plus récent de ce papier est Bosilca, Delmas, Dongarra, et Langou " tolérance de faute basée sur L'algorithme appliqué au calcul haute performance ".
l'Écriture de code pour les environnements radioactifs n'est pas vraiment différent que d'écrire du code pour tout type de mission-critique la demande.
En plus de ce qui a déjà été mentionné, voici quelques conseils:
- utilisez les mesures de sécurité quotidiennes "bread & butter" qui devraient être présentes sur tout système intégré semi-professionnel: chien de garde interne, détection de basse tension interne, moniteur d'horloge interne. Ces choses ne devraient pas même besoin d'être mentionné dans l'année 2016 et ils sont la norme sur à peu près tous les microcontrôleurs modernes.
- si vous avez un MCU orienté sécurité et/ou automobile, il aura certaines caractéristiques de chien de garde, comme une fenêtre de temps donnée, à l'intérieur de laquelle vous avez besoin de rafraîchir le chien de garde. Ceci est préférable si vous avez un système en temps réel critique pour votre mission.
- en général, utiliser un MCU adapté à ce genre de systèmes, et non pas une quelconque fluff Générique grand public vous avez reçu un paquet de Corn flakes. Presque tous les fabricants de MCU ont aujourd'hui des MCU spécialisés conçus pour des applications de sécurité (TI, Freescale, Renesas, ST, Infineon etc.). Ceux-ci ont beaucoup de dispositifs de sécurité intégrés, y compris des cœurs de verrouillage-pas: ce qui signifie qu'il ya 2 cœurs CPU exécutant le même code, et ils doivent être d'accord avec l'autre.
-
IMPORTANT: vous devez assurer l'intégrité des registres MCU internes. Tous les registres de contrôle et d'état de les périphériques matériels qui peuvent être écrits peuvent être situés dans la mémoire RAM, et sont donc vulnérables.
pour vous protéger contre les corruptions de registres, choisissez de préférence un microcontrôleur avec les caractéristiques" écrire une fois " intégrées aux registres. En outre, vous devez stocker les valeurs par défaut de tous les registres matériels dans NVM et copier ces valeurs vers vos registres à intervalles réguliers. Vous pouvez assurer l'intégrité des variables importantes de la même manière.
Note: toujours utiliser la programmation défensive. Ce qui signifie que vous devez configurer tous les registres dans le MCU et pas seulement ceux utilisés par l'application. Vous ne voulez pas qu'un périphérique matériel se réveille soudainement.
-
il existe toutes sortes de méthodes pour vérifier la présence d'erreurs dans la mémoire vive ou les NVM: checksums, "walking patterns", ECC logiciel, etc. La meilleure solution aujourd'hui est de ne pas utiliser l'un de ces, mais l'utilisation d'un MCU avec contrôle ECC intégré et contrôles similaires. Parce que faire cela dans le logiciel est complexe, et le contrôle d'erreur en lui-même pourrait donc introduire des bogues et des problèmes inattendus.
- utilisez la redondance. Vous pouvez stocker à la fois de la mémoire volatile et non volatile dans deux segments "miroirs" identiques, qui doivent toujours être équivalents. Chaque segment pourrait avoir un checksum CRC attaché.
- éviter d'utiliser des mémoires externes à l'extérieur du MCU.
- Implémenter un gestionnaire de routine / d'exception d'interruption de service par défaut pour toutes les interruptions/exceptions possibles. Même ceux que vous n'utilisez pas. La routine par défaut ne devrait rien faire à part désactiver sa propre source d'interruption.
-
Comprendre et adopter le concept de la programmation défensive. Cela signifie que votre programme doit traiter tous les cas possibles, même ceux qui ne peuvent pas se produire en théorie. Exemples .
microprogramme de haute qualité critique détecte autant d'erreurs que possible, puis les ignore d'une manière sûre.
- N'écrivez jamais de programmes qui s'appuient sur un comportement mal spécifié. Il est probable qu'un tel comportement pourrait changer radicalement avec des changements de matériel inattendus causés par le rayonnement ou EMI. La meilleure façon de s'assurer que votre programme est libre de telles conneries est d'utiliser un standard de codage comme MISRA, avec un outil d'analyse statique. Ce sera aide également avec la programmation défensive et avec le désherbage des bogues (pourquoi ne voudriez-vous pas détecter des bogues dans n'importe quel type d'application?).
-
IMPORTANT: N'implémentez aucune dépendance des valeurs par défaut des variables de durée de stockage statique. C'est-à-dire, ne faites pas confiance au contenu par défaut du
.dataou.bss. Il pourrait y avoir n'importe quel temps entre le point d'initialisation au point où la variable est réellement utilisée, il pourrait y avoir beaucoup de temps pour que le bélier soit corrompu. Au lieu de cela, écrivez le programme de sorte que toutes ces variables soient définies à partir de NVM dans l'exécution, juste avant le moment où une telle variable est utilisée pour la première fois.en pratique cela signifie que si une variable est déclarée à la portée du fichier ou comme
static, vous ne devriez jamais utiliser=pour l'initialiser (ou vous pourriez, mais il est inutile, parce que vous ne pouvez pas compter sur la valeur de toute façon). Réglez-le toujours à l'avance, juste avant l'utilisation. Si il est possible de mettre à jour ces variables à plusieurs reprises à partir de NVM, puis de le faire.de la même façon en C++, ne vous fiez pas aux constructeurs pour les variables de durée de stockage statique. Demandez au(X) constructeur (s) d'appeler une routine publique de "mise en place", que vous pouvez également appeler plus tard à l'exécution, directement à partir de l'application appelant.
si possible, supprimer le code de démarrage" copy-down "qui initialise
.dataet.bss(et appelle les constructeurs C++) entièrement, de sorte que vous obtenez des erreurs de linker si vous écrivez le code en se basant sur tel. De nombreux compilateurs ont la possibilité de sauter cette étape, habituellement appelée "démarrage minimal/rapide" ou similaire.cela signifie que toute bibliothèque externe doit être vérifiée afin de ne pas contenir une telle confiance.
-
implémenter et définir un état sûr pour le programme, où vous retournerez en cas d'erreurs critiques.
- la mise en Œuvre de un système de rapport d'erreur / journal des erreurs est toujours utile.
il peut être possible d'utiliser C pour écrire des programmes qui se comportent avec robustesse dans de tels environnements, mais seulement si la plupart des formes d'optimisation du compilateur sont désactivées. Optimiser les compilateurs sont conçus pour remplacer de nombreux modèles de codage apparemment redondants par des modèles "plus efficaces", et peut n'avoir aucune idée que la raison pour laquelle le programmeur teste x==42 quand le compilateur sait qu'il n'y a aucun moyen x pourrait éventuellement tenir autre chose est parce que le programmeur veut empêcher la l'exécution de certains codes avec x contenant une autre valeur--même dans les cas où la seule façon de conserver cette valeur serait que le système reçoive une sorte de bug électrique.
déclarer des variables comme volatile est souvent utile, mais peut ne pas être une panacée.
Il est particulièrement important de noter que le codage Sécuritaire exige souvent que les
les opérations ont des dispositifs de verrouillage matériel qui nécessitent plusieurs étapes pour activer,
et que le code soit écrit motif:
... code that checks system state
if (system_state_favors_activation)
{
prepare_for_activation();
... code that checks system state again
if (system_state_is_valid)
{
if (system_state_favors_activation)
trigger_activation();
}
else
perform_safety_shutdown_and_restart();
}
cancel_preparations();
si un compilateur traduit le code de manière relativement littérale, et si tous
les vérifications de l'état du système sont répétées après le prepare_for_activation() ,
le système peut être robuste contre presque n'importe quel incident simple plausible,
même ceux qui corrompraient arbitrairement le compteur et la pile de programmes. Si
un problème survient juste après un appel à prepare_for_activation() , qui impliquerait
cette activation aurait été appropriée (puisqu'il n'y a pas d'autre raison
prepare_for_activation() aurait été appelé avant le bug). Si l'
glitch provoque le code pour atteindre prepare_for_activation() de façon inappropriée, mais il
sont pas glitch événements, il n'y aurait aucun moyen pour le code par la suite
atteindre trigger_activation() sans avoir passé par le contrôle de validation ou appeler cancel_préparations en premier [si la pile est défectueuse, l'exécution peut se faire à un endroit juste avant trigger_activation() après le contexte qui renvoie prepare_for_activation() , mais l'appel à cancel_preparations() aurait se produit entre les appels à prepare_for_activation() et trigger_activation() , ce qui rend ce dernier appel inoffensif.
ce code peut être sûr dans le C traditionnel, mais pas avec les compilateurs C modernes. De tels compilateurs peuvent être très dangereux dans ce genre d'environnement parce que agressif ils s'efforcent de n'inclure que du code qui sera pertinent dans des situations qui pourraient venir à travers un mécanisme bien défini et dont les conséquences résultantes seraient également bien définies. Code dont le but serait de détecter et de nettoyer après des échecs peut, dans certains cas, finir par rendre les choses pire. Si le compilateur détermine que la tentative de récupération pourrait dans certains cas invoquer un comportement non défini, il peut en déduire que les conditions qui nécessiteraient une telle récupération dans de tels cas ne peuvent pas se produire, éliminant ainsi le code qui aurait vérifié pour eux.
C'est un sujet extrêmement vaste. Fondamentalement, vous ne pouvez pas vraiment récupérer de la corruption de mémoire, mais vous pouvez au moins essayer de fail promptly . Voici quelques techniques que vous pourriez utiliser:
-
la somme de contrôle des données constantes . Si vous avez des données de configuration qui restent constantes pendant longtemps( y compris les registres matériels que vous avez configurés), calculez leur somme de contrôle lors de l'initialisation et vérifiez périodiquement. Quand vous voyez un décalage, il est temps de ré-initialiser ou de réinitialiser.
-
variables de stock avec redondance . Si vous avez une variable importante
x, écrivez sa valeur dansx1,x2etx3et lisez-la comme(x1 == x2) ? x2 : x3. -
mettre en œuvre programme de contrôle de débit . XOR un drapeau mondial avec une valeur unique en fonctions/branches importantes appelées à partir de la boucle principale. L'exécution du programme dans un environnement sans rayonnement avec une couverture d'essai de près de 100% devrait vous donner la liste des valeurs acceptables du drapeau à la fin du cycle. Réinitialisez si vous voyez des déviations.
-
surveiller le pointeur de la pile . Au début de la boucle principale, de comparer le pointeur de pile avec sa valeur attendue. Réinitialiser sur déviation.
ce qui pourrait vous aider est un chien de garde . Les Watchdogs ont été largement utilisés dans l'informatique industrielle dans les années 1980. Les pannes matérielles étaient alors beaucoup plus fréquentes - une autre réponse fait également référence à cette période.
un chien de garde est une fonction combinée matériel/logiciel. Le matériel est un simple compteur qui décompte d'un nombre (disons 1023) à zéro. TTL ou d'une autre logique peut être utilisé.
le logiciel a été conçu comme tel qu'une routine surveille le bon fonctionnement de tous les systèmes essentiels. Si cette routine se termine correctement = trouve que l'ordinateur fonctionne correctement, il renvoie le compteur à 1023.
la conception globale est telle que dans des circonstances normales, le logiciel empêche que le compteur matériel atteindra zéro. Dans le cas où le compteur atteint zéro, le matériel du compteur exécute sa tâche unique et réinitialise l'ensemble du système. À partir d'un compteur point de vue, zéro égale 1024 et le compteur continue de décompter.
ce chien de garde s'assure que l'ordinateur attaché est redémarré dans de nombreux cas de défaillance. Je dois avouer que je ne suis pas familier avec le matériel qui est capable d'effectuer une telle fonction sur les ordinateurs d'aujourd'hui. Les Interfaces avec le matériel externe sont maintenant beaucoup plus complexes qu'elles ne l'étaient auparavant.
Un désavantage inhérent du chien de garde est que le système n'est pas disponible à partir du moment où il échoue jusqu'à ce que le compteur de chien de garde atteint zéro + temps de redémarrage. Bien que ce délai soit généralement beaucoup plus court que n'importe quelle intervention externe ou humaine, l'équipement appuyé devra être en mesure d'aller de l'avant sans contrôle informatique pour cette période.
cette réponse suppose que vous êtes soucieux d'avoir un système qui fonctionne correctement, au - delà d'avoir un système qui est le coût minimum ou rapide; la plupart des gens qui jouent avec des choses radioactives valeur exactitude / sécurité sur la vitesse / coût
plusieurs personnes ont suggéré des changements de matériel que vous pouvez faire (bien-il y a beaucoup de bonnes choses ici dans les réponses déjà et je n'ai pas l'intention de répéter tout cela), et d'autres ont suggéré la redondance (excellent en principe), mais je ne pense pas que quiconque ait suggéré comment cette redondance pourrait fonctionner dans la pratique. Comment avez-vous basculement? Comment savoir si quelque chose a "mal tourné"? De nombreuses technologies fonctionnent sur la base de tout va fonctionner, et l'échec est donc une chose délicate à traiter. Cependant, certaines technologies de calcul distribué conçu pour l'échelle s'attendre échec (après tout avec assez d'échelle, la défaillance d'un noeud de beaucoup est inévitable avec n'importe quel MTBF pour un seul noeud); vous pouvez l'exploiter pour votre environnement.
voici quelques idées:
-
" assurez-vous que tout votre matériel est répliqué
nfois (oùnest supérieur à 2, et de préférence Impair), et que chaque élément matériel peut communiquer entre eux. Ethernet est une façon évidente de le faire, mais il y a beaucoup d'autres routes beaucoup plus simples qui donneraient une meilleure protection (par exemple CAN). Minimiser composants communs (même alimentations). Cela peut signifier l'échantillonnage d'entrées ADC dans plusieurs endroits par exemple. -
assurez-vous que votre état d'application est en un seul endroit, p.ex. dans une machine à états finis. Cela peut être entièrement basé sur la mémoire vive, mais cela n'empêche pas un stockage stable. Il sera ainsi stocké à plusieurs endroits.
-
adopter un protocole de quorum pour les changements d'état. Voir radeau exemple. Comme vous travaillez en C++, il y a des bibliothèques bien connues pour cela. Les modifications à la FSM ne seraient faites que si la majorité des noeuds sont d'accord. Utiliser une bibliothèque pour la pile de protocole et le collège protocole plutôt que de faire vous-même, ou votre bon travail sur la redondance sera perdu lorsque le quorum protocole raccroche.
-
S'assurer que vous contrôlez (par exemple CRC/SHA) votre FSM, et stocker le CRC / SHA dans la FSM elle-même (ainsi que transmettre dans le message, et vérifier les messages eux-mêmes). Demandez aux noeuds de vérifier régulièrement leur FSM par rapport à ces checksum, checksum messages entrants, et vérifiez que leur checksum correspond au checksum du quorum.
-
construisez autant de vérifications internes que possible dans votre système, en créant des noeuds qui détectent leur propre redémarrage en panne (c'est mieux que de continuer à travailler à moitié pourvu que vous ayez assez de noeuds). Essayer de les laisser retirez-vous proprement du quorum pendant le redémarrage au cas où ils ne reviendraient pas. Lors du redémarrage, demandez-leur de vérifier l'image du logiciel (et tout ce qu'ils chargent) et de faire un test complet avant de se présenter de nouveau au quorum.
-
utilisez le matériel pour vous soutenir, mais faites-le avec soin. Vous pouvez obtenir ECC RAM, par exemple, et régulièrement lire/écrire à travers elle pour corriger les erreurs ECC (et la panique si l'erreur est uncorrectable). Cependant (à partir de mémoire vive) la mémoire vive statique est beaucoup plus tolérante aux rayonnements ionisants que la mémoire vive statique.il est donc préférable d'utiliser la mémoire vive statique plutôt que la mémoire vive statique. Voir le premier point sous "choses que je ne ferais pas".
disons que vous avez 1% de chance d'échec d'un noeud donné dans la journée, et faisons comme si vous pouviez rendre les échecs entièrement indépendants. Avec 5 noeuds, vous aurez besoin de trois pour échouer en un jour, qui est un .Zero zero zero zero un% chance. Avec plus, eh bien, vous obtenez l'idée.
Choses que j'ai pas :
-
sous-estimer la valeur de ne pas avoir le problème pour commencer. sauf si le poids est un problème, un gros bloc de métal autour de votre appareil va être une solution beaucoup moins cher et plus fiable qu'une équipe de programmeurs peut venir avec. Il en va de même pour le couplage optique des entrées D'EMI, etc. Quoi qu'il en soit, tentez lors de l'approvisionnement de vos composants à la source ceux qui sont le mieux cotés contre le rayonnement ionisant.
-
Rouler vos propres algorithmes de . Les gens ont fait ce genre de choses avant. Utilisez leur travail. La tolérance aux erreurs et les algorithmes distribués sont difficiles. Utilisez le travail d'autres personnes dans la mesure du possible.
-
utilisez des paramètres de compilateurs compliqués dans l'espoir naïf que vous détectiez plus d'Échecs. si vous êtes chanceux, vous pouvez détecter plus d'Échecs. Plus probablement, vous utiliserez un chemin de code dans le compilateur qui a été moins testé, particulièrement si vous l'avez roulé vous-même.
-
utilisez des techniques qui n'ont pas été testées dans votre environnement. la plupart des gens qui écrivent des logiciels de haute disponibilité doivent simuler des modes de défaillance pour vérifier que leur système fonctionne correctement, et rater de nombreux modes de défaillance en conséquence. Vous êtes dans la 'la chance' d'avoir de fréquents échecs sur demande. Donc tester chaque technique, et s'assurer que son application réelle améliore MTBF d'une quantité qui dépasse la complexité de l'introduire (avec la complexité vient bugs). Surtout appliquez ceci à mes conseils sur les algorithmes de quorum etc.
puisque vous demandez spécifiquement des solutions logicielles, et que vous utilisez C++, pourquoi ne pas utiliser la surcharge de l'opérateur pour créer vos propres types de données sécuritaires? Par exemple:
au lieu d'utiliser uint32_t (et double , int64_t etc), Faites votre propre SAFE_uint32_t qui contient un multiple (minimum de 3) de uint32_t. Surcharger toutes les opérations que vous voulez (* + - / << >> = == != etc) pour effectuer, et faire les opérations surchargées effectuer indépendamment sur chaque valeur interne, c'est-à-dire ne le faites pas une seule fois et copiez le résultat. Avant et après, vérifiez que toutes les valeurs internes correspondent. Si les valeurs ne correspondent pas, vous pouvez mettre à jour le mauvais à la valeur la plus courante. Si il n'y a pas plus de valeur commune, vous pouvez informer qu'il y a une erreur.
de cette façon, il n'importe pas si la corruption se produit dans L'ALU, registres, RAM, ou sur un bus, vous aurez encore de multiples tentatives et une très bonne chance de attraper des erreurs. Note cependant, bien que cela ne fonctionne que pour les variables que vous pouvez remplacer votre pointeur de pile par exemple sera toujours sensible.
une histoire secondaire: j'ai rencontré un problème similaire, également sur une vieille puce de bras. Il s'est avéré que C'était une chaîne d'outils qui utilisait une ancienne version de GCC qui, avec la puce spécifique que nous avons utilisée, a déclenché un bug dans certains cas de bord qui pourrait (parfois) corrompre les valeurs passées en fonctions. Assurez-vous que votre appareil n'a pas de problèmes avant le blâmer sur la radio-activité, et oui, parfois c'est un bug de compilateur=)
avertissement: Je ne suis pas un professionnel de la radioactivité et je n'ai pas travaillé pour ce genre d'application. Mais j'ai travaillé sur les erreurs légères et la redondance pour l'archivage à long terme des données critiques, qui est quelque peu lié (même problème, objectifs différents).
le principal problème avec la radioactivité à mon avis est que la radioactivité peut changer de bits, donc la radioactivité peut/va altérer n'importe quelle mémoire numérique . Ces erreurs sont généralement appelées douce erreurs , pourriture de bits, etc.
la question est alors: comment calculer de manière fiable quand votre mémoire n'est pas fiable?
pour réduire de façon significative le taux d'erreurs non intentionnelles (au détriment des frais généraux de calcul puisqu'il s'agira principalement de solutions logicielles), vous pouvez soit:
-
s'appuient sur le bon vieux plan de licenciement , et plus spécifiquement le plus efficace "error correcting codes " (même but, mais des algorithmes plus intelligents de sorte que vous pouvez récupérer plus de bits avec moins de redondance). C'est parfois (à tort) aussi appelé checksumming. Avec ce genre de solution, vous devrez stocker l'état complet de votre programme à tout moment dans une variable/classe de maître (ou une structure?), calculer un CEC, et vérifier que le CEC est correct avant de faire quoi que ce soit, et si non, réparer champ. Cette solution ne garantit toutefois pas que votre logiciel peut fonctionner (simplement qu'il fonctionnera correctement lorsqu'il le peut, ou qu'il cesse de fonctionner si ce n'est pas le cas, car ECC peut vous dire si quelque chose ne va pas, et dans ce cas, vous pouvez arrêter votre logiciel afin que vous n'obteniez pas de faux résultats).
-
ou vous pouvez utiliser resilient algorithmic data structures , qui garantissent, jusqu'à une certaine limite, que votre programme donnera encore correct les résultats, même en présence d'erreurs logicielles. Ces algorithmes peuvent être considérés comme un mélange de structures algorithmiques communes avec des schémas ECC nativement mélangés, mais c'est beaucoup plus résilient que cela, parce que le schéma de résilience est étroitement lié à la structure, de sorte que vous n'avez pas besoin d'encoder des procédures supplémentaires pour vérifier L'ECC, et généralement ils sont beaucoup plus rapides. Ces structures fournissent un moyen d'assurer que votre programme fonctionnera sous n'importe quelle condition, jusqu'à la limite théorique de soft erreur. Vous pouvez également mélanger ces structures résilientes avec le schéma redondance/ECC pour une sécurité supplémentaire (ou encoder vos structures de données les plus importantes en tant que résilient, et le reste, les données extensibles que vous pouvez recalculer à partir des structures de données principales, en tant que structures de données normales avec un peu de ECC ou un contrôle de parité qui est très rapide à calculer).
si vous êtes intéressé par les structures de données résilientes (qui est un nouveau domaine récent, mais passionnant, dans algorithmics and redondance engineering), je vous conseille de lire les documents suivants:
-
Christiano, P., Demaine, E. D., & Kishore, S. (2011). Structures de données tolérantes aux failles sans perte avec surcharge additive. Dans les Algorithmes et Structures de Données (pp. 243-254). Springer Berlin Heidelberg.
-
Ferraro-Petrillo, U., Grandoni, F., & Italiano, G. F. (2013). Les structures de données de résilience à mémoire de défauts: une étude expérimentale de dictionnaires. Journal of Experimental Algorithmics (JEA), 18, 1-6.
-
Italiano, G. F. (2010). Algorithmes et structures de données résilients. Dans les Algorithmes et Complexité (pp. 13-24). Springer Berlin Heidelberg.
si vous souhaitez en savoir plus sur le domaine des structures de données élastiques, vous pouvez consulter les travaux de Giuseppe F. Italiano (et travailler votre chemin à travers les réfs) et le Faulty-RAM model (présenté dans Finocchi et al. 2005; Finocchi et Italiano 2008).
/ EDIT: j'ai illustré la prévention/récupération des erreurs soft principalement pour la mémoire RAM et le stockage de données, mais je n'ai pas parlé de calcul (CPU), des erreurs . D'autres réponses déjà pointées à l'aide de transactions atomiques comme dans les bases de données, donc je vais proposer un autre, schéma plus simple: redondance et vote majoritaire .
l'idée est que vous simplement faites x fois le même calcul pour chaque calcul que vous devez faire, et stocker le résultat dans x variables différentes (avec x >= 3). Vous pouvez ensuite comparer vos variables x :
- s'ils sont tous d'accord, alors il n'y a aucune erreur de calcul.
- s'ils ne sont pas d'accord, alors vous pouvez utiliser un vote majoritaire pour obtenir la valeur correcte, et puisque cela signifie que le calcul a été partiellement corrompu, vous pouvez également déclencher un balayage d'état système/programme pour vérifier que le reste est ok.
- si le vote majoritaire ne peut pas déterminer un gagnant( toutes les valeurs x sont différentes), alors c'est un signal parfait pour vous devez déclencher la procédure de sécurité intégrée (redémarrage, alerte à l'utilisateur, etc.).
ce schéma de redondance est très rapide comparé à ECC (pratiquement O(1)) et il vous fournit un signal clair quand vous avez besoin de failsafe . Le vote majoritaire est aussi (presque) garanti de ne jamais produire la sortie corrompue et aussi à récupérer de calcul mineur erreurs , parce que la probabilité que les calculs x donnent la même sortie est infinitésimale (parce qu'il y a une énorme quantité de sorties possibles, il est presque impossible d'obtenir au hasard 3 fois la même, encore moins de chances si x > 3).
donc avec vote majoritaire vous êtes à l'abri de la sortie corrompue, et avec la redondance x == 3, vous pouvez récupérer 1 erreur (avec x == 4 il sera 2 erreurs récupérable, etc -- l'équation exacte est nb_error_recoverable == (x-2) où x est le nombre de calcul répétitions parce que vous avez besoin d'au moins 2 calculs d'accord pour récupérer en utilisant le vote majoritaire).
l'inconvénient est que vous devez calculer x fois au lieu d'une fois, de sorte que vous avez un coût de calcul supplémentaire, mais la complexité linéaire de sorte que asymptotiquement vous ne perdez pas beaucoup pour les avantages que vous gagnez. Un moyen rapide de faire un vote majoritaire est de calculer le mode sur un tableau, mais vous pouvez également utiliser un filtre médian.
Aussi, si vous voulez faire très sûr que les calculs sont effectués correctement, si vous pouvez faire votre propre matériel, vous pouvez construire votre appareil avec X CPUs, et le câblage du système de sorte que les calculs sont automatiquement dupliqués à travers les X CPUs avec un vote majoritaire fait mécaniquement à la fin (en utilisant et/ou portes par exemple). Cela est souvent mis en œuvre dans les avions et les appareils critiques (voir Triple redondance modulaire ). De cette façon, vous n'auriez pas de frais généraux de des calculs supplémentaires seront effectués en parallèle), et vous disposez d'une autre couche de protection contre les erreurs légères (puisque la duplication des calculs et le vote majoritaire seront gérés directement par le matériel et non par le logiciel-qui peut plus facilement être corrompu puisqu'un programme est simplement des bits stockés en mémoire...).
vous voulez 3 + machines esclaves avec un maître en dehors de l'environnement de rayonnement. Tous les e/s passent par le master qui contient un mécanisme de vote et/ou de Ré-essai. Les esclaves doivent avoir chacun un chien de Garde matériel et l'appel à les bousculer doit être entouré de CRCs ou autres pour réduire la probabilité de cogner involontairement. Le cognement doit être commandé par le maître, de sorte que la perte de connexion avec le maître égale redémarrage en quelques secondes.
un avantage de ce la solution est que vous pouvez utiliser la même API pour le maître comme pour les esclaves, la redondance devient une fonctionnalité transparente.
Edit: D'après les commentaires, je ressens le besoin de clarifier les "CRC idée."La possibilité pour l'esclave de cogner son propre chien de garde est proche de zéro si vous entourez la bosse avec des contrôles CRC ou digest sur des données aléatoires du maître. Ces données aléatoires ne sont envoyées par le maître que lorsque l'esclave examiné est aligné avec les autres. Le données aléatoires et CRC/digest sont immédiatement effacées après chaque bosse. La fréquence des bosses maître-esclave devrait être plus de double le temps d'arrêt de l'observateur. Les données envoyées par le capitaine sont générées de façon unique à chaque fois.
Un point que personne ne semble avoir mentionné. Vous dites que vous développez en GCC et que vous compilez sur ARM. Comment savez-vous que vous n'avez pas de code qui fait des suppositions sur la RAM libre, la taille de l'entier, la taille du pointeur, combien de temps il faut pour faire une certaine opération, combien de temps le système fonctionnera en continu, ou divers trucs comme ça? C'est un problème très commun.
la réponse est habituellement le test automatisé de l'unité. Ecrire Des harnais d'essai qui exercent le code sur le système de développement, puis exécuter les mêmes harnais de test sur le système cible. Cherchez les différences!
vérifiez également les errata sur votre appareil embarqué. Vous pouvez trouver qu'il y a quelque chose à propos de "ne faites pas cela parce qu'il va se planter, donc activez cette option de compilateur et le compilateur va travailler autour de lui".
en bref, votre source la plus probable de pannes est des bugs dans votre code. Jusqu'à ce que vous avez fait sacrément sûr que ce n'est pas le cas, ne vous inquiétez pas (encore) à propos des modes de défaillance plus ésotériques.
Que Diriez-vous d'exécuter plusieurs instances de votre application. Si les accidents sont dus à des changements de bits de mémoire aléatoires, il y a des chances que certaines de vos instances de l'application s'en sortent et produisent des résultats précis. Il est probablement assez facile (pour quelqu'un avec l'arrière-plan statistique) de calculer combien d'instances avez-vous besoin de la probabilité bit flop donnée pour atteindre l'erreur globale aussi minuscule que vous le souhaitez.
ce que vous demandez est un sujet assez complexe - pas facile à répondre. D'autres réponses sont acceptables, mais elles ne couvrent qu'une petite partie de toutes les choses que vous devez faire.
comme vu dans les commentaires , il n'est pas possible de corriger les problèmes de matériel à 100%, mais il est possible avec haute probabily de les réduire ou de les attraper en utilisant diverses techniques.
si j'étais vous, je créerais le logiciel de la plus haute intégrité de sécurité niveau niveau (SIL-4). Obtenez le document CEI 61513 (pour l'industrie nucléaire) et suivez-le.
Quelqu'un a mentionné utiliser des puces plus lentes pour empêcher les ions de retourner des bits aussi facilement. De la même manière peut-être utiliser un cpu/ram spécialisé qui utilise en fait plusieurs bits pour stocker un seul bit. Il est donc très peu probable que tous les bits soient renversés. Donc 1 = 1111 mais aurait besoin d'être frappé 4 fois pour réellement flippé. (4 pourrait être un mauvais nombre puisque si 2 bits sont renversés son déjà ambigu). Donc, si vous allez avec 8, vous obtenez 8 fois moins de ram et une fraction de temps d'accès plus lent, mais une représentation de données beaucoup plus fiable. Vous pourriez probablement faire cela à la fois au niveau du Logiciel avec un compilateur spécialisé (allouer x quantité plus d'espace pour tout) ou l'implémentation du langage (écrire des wrappers pour les structures de données qui attribuent les choses de cette façon). Ou du matériel spécialisé qui a la même structure logique mais qui le fait dans le micrologiciel.
peut-être serait-il utile de savoir ce que signifie pour le matériel d'être"conçu pour cet environnement". Comment corrige-t-il et / ou indique-t-il la présence d'erreurs SEU ?
à un projet lié à l'exploration spatiale, nous avions un MCU personnalisé, qui soulèverait une exception/interruption sur les erreurs SEU, mais avec un certain retard, c'est-à-dire que certains cycles peuvent passer/les instructions être exécutées après celui insn qui a causé l'exception SEU.
particulièrement vulnérable était le cache de données, de sorte qu'un gestionnaire invaliderait la ligne de cache incriminée et relancerait le programme. C'est seulement que, en raison de la nature imprécise de l'exception, la séquence d'insns dirigés par l'exception soulevant insn peut ne pas être redémarré.
nous avons identifié les séquences dangereuses (non redémarrables) (comme lw , 0x0() , suivi d'un insn, qui modifie et n'est pas dépendant des données de ), et j'ai fait des modifications à GCC, donc de telles séquences ne sont pas se produisent (par exemple en dernier recours, en séparant les deux insns par un nop ).
Juste quelque chose à considérer ...
si votre matériel tombe en panne, vous pouvez utiliser le stockage mécanique pour le récupérer. Si votre base de code est petite et dispose d'un espace physique, vous pouvez utiliser une mémoire mécanique.
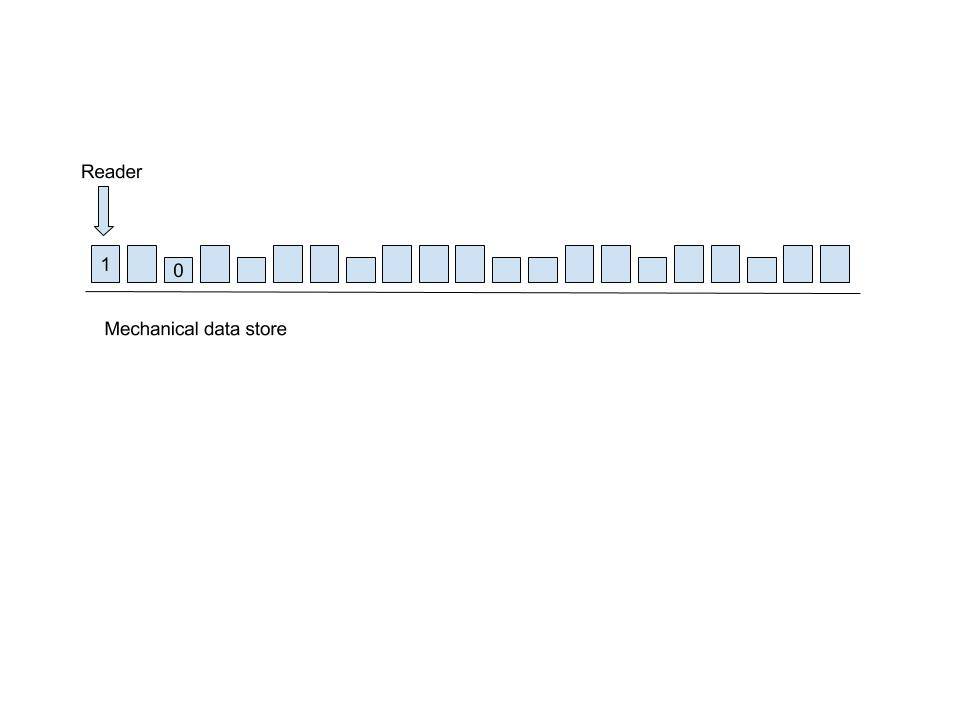
il y aura une surface de matériau qui ne sera pas affectée par le rayonnement. Plusieurs vitesses seront là. Un lecteur mécanique fonctionnera sur tous les engrenages et sera flexible pour se déplacer vers le haut et vers le bas. Vers le bas signifie il est 0 et signifie qu'il est de 1. À partir de 0 et 1, vous pouvez générer votre base de code.
utiliser un planificateur cyclique . Cela vous donne la possibilité d'ajouter un entretien régulier fois pour vérifier l'exactitude des données critiques. Le problème le plus souvent rencontré est la corruption de la pile. Si votre logiciel est cyclique, vous pouvez réinitialiser la pile entre les cycles. Ne pas réutiliser les piles pour les appels d'interruption, configurer une pile séparée de chaque appel d'interruption important.
similaire au concept Watchdog est deadline timers. Démarrer une horloge matérielle avant d'appeler une fonction. Si la fonction ne retourne pas avant la date limite, le timer interrompt alors recharger la pile et réessayer. Si elle échoue encore après 3/5 Essais, vous devez recharger à partir de ROM.
divisez votre logiciel en pièces et isolez ces pièces pour utiliser des zones de mémoire et des délais d'exécution séparés (surtout dans un environnement de contrôle). Exemple: acquisition du signal, pré-traitement des données, algorithme principal et mise en œuvre/transmission du résultat. Cela signifie un un échec dans une partie ne causera pas d'échec dans le reste du programme. Donc, pendant que nous réparons l'acquisition du signal, le reste des tâches se poursuit sur des données périmées.
Tout doit CRCs. Si vous exécutez à partir de RAM même votre .le texte a besoin D'un CRC. Si vous utilisez un planificateur cyclique, Vérifiez régulièrement les CRC. Certains compilateurs (pas GCC) peuvent générer des CRCs pour chaque section et certains processeurs ont du matériel dédié pour faire des calculs CRC, mais je suppose que cela tomberait du côté de la portée de votre question. La vérification de CRCs demande également au contrôleur ECC en mémoire de réparer les erreurs de bits simples avant qu'elles ne deviennent un problème.
tout d'Abord, la conception de votre application autour de l'échec . Assurez-vous que dans le cadre du fonctionnement normal du flux, il s'attend à réinitialiser (selon votre application et le type de défaillance soit douce ou dure). C'est difficile d'obtenir la perfection: les opérations critiques qui nécessitent un certain degré de transactionnalité peuvent devoir être vérifiées et ajustées au niveau de l'assemblage afin qu'une interruption à un point clé ne puisse pas donner lieu à des commandes externes incohérentes. Fail fast dès qu'un non récupérable altération de la mémoire ou déviation du flux de contrôle est détecté. Les erreurs de journal si possible.
deuxièmement, si possible, corriger la corruption et continuer . Cela signifie vérifier et fixer les tables constantes (et le code de programme si vous le pouvez) souvent; peut-être avant chaque opération majeure ou sur une interruption chronométrée, et le stockage des variables dans les structures qui autocorrect (encore une fois avant chaque opération majeure ou sur une interruption chronométrée prendre un vote à la majorité de 3 et corriger si est une déviation unique). Enregistrez les corrections si possible.
Troisièmement, échec de test . Mettre en place un répétable environnement de test qui renverse bits dans la mémoire psuedo-aléatoirement. Cela vous permettra de répliquer des situations de corruption et d'aider à concevoir votre application autour d'eux.
étant donné les commentaires de supercat, les tendances des compilateurs modernes, et d'autres choses, je serais tenté de revenir à l'Antiquité et d'écrire le code entier en assemblée et allocations de mémoire statique partout. Pour ce genre de fiabilité absolue, je pense que l'assemblage n'engage plus une grande différence de pourcentage du coût.
Voici énorme quantité de réponses, mais je vais essayer de résumer mes idées à ce sujet.
quelque chose tombe en panne ou ne fonctionne pas correctement pourrait être le résultat de vos propres erreurs - alors il devrait être facile de corriger lorsque vous localisez le problème. Mais il y a aussi la possibilité de pannes matérielles - et c'est difficile, voire impossible à corriger dans l'ensemble.
je recommande d'abord d'essayer de saisir la situation problématique par journalisation (stack, registers, appels de fonction) - soit en les enregistrant quelque part dans le fichier, ou en les transmettant d'une manière ou d'une autre directement ("oh Non-Je m'écrase").
récupération à partir d'une telle situation d'erreur est soit redémarrage (si le logiciel est encore vivant et coup de pied) ou réarmement du matériel (par exemple, les chiens de garde hw). Plus facile de commencer par le premier.
si le problème est lié au matériel - alors la journalisation devrait vous aider à identifier dans quelle fonction le problème d'appel se produit et qui peut vous donner à l'intérieur de la connaissance de ce n'est pas de travail et où.
aussi si le code est relativement complexe - il est logique de" diviser pour mieux régner "- ce qui signifie que vous supprimez / désactivez certains appels de fonction où vous soupçonnez que le problème est - typiquement désactivant la moitié du code et activant une autre moitié - vous pouvez obtenir le genre de décision" fonctionne " / "ne fonctionne pas" après quoi vous pouvez vous concentrer sur une autre moitié du code. (Où le problème est)
si le problème se produit après un certain temps - alors le débordement de la pile peut être soupçonné - alors il est préférable de surveiller les registres de point de cheminée-si elles poussent constamment.
et si vous parvenez à minimiser complètement votre code jusqu'à ce que" hello world "type d'application - et il est toujours en échec aléatoire - puis des problèmes de matériel sont attendus - et il doit y avoir" hardware upgrade " - ce qui signifie inventer un tel cpu / ram / ... -combinaison matérielle qui tolère rayonnement mieux.
la chose la plus importante est probablement comment vous obtenez votre les logs de retour si la machine est complètement arrêtée / réinitialisée / ne fonctionne pas - probablement la première chose que bootstap devrait faire - est une tête de retour à la maison si la situation problématique est cernée.
S'il est également possible dans votre environnement de transmettre un signal et de recevoir une réponse - vous pourriez essayer de construire une sorte d'environnement de débogage à distance en ligne, mais alors vous devez avoir au moins des médias de communication en état de fonctionnement et un processeur/ une ram en état de fonctionnement. Et en déboguant à distance je signifie soit gdb / gdb stub type d'approche ou votre propre mise en œuvre de ce dont vous avez besoin pour revenir de votre application (par exemple, fichiers journaux de téléchargement, pile d'appels de téléchargement, ram de téléchargement, redémarrer)
j'ai vraiment lu beaucoup de réponses!
Voici mon 2 cent: construire un modèle statistique de la mémoire/anomalie de registre, en écrivant un logiciel pour vérifier la mémoire ou d'effectuer des comparaisons fréquentes de registre. En outre, de créer un émulateur, dans le style d'une machine virtuelle où vous pouvez expérimenter avec la question. Je suppose que si vous variez la taille de la jonction, la fréquence de l'horloge, le vendeur, le boîtier, etc observerait un comportement différent.
même notre la mémoire de PC de bureau a un certain taux de défaillance, qui cependant n'altère pas le travail quotidien.