Apache spark peut-il fonctionner sans hadoop?
8 réponses
Spark peut fonctionner sans Hadoop mais certaines de ses fonctionnalités repose sur le code de Hadoop (par exemple la manipulation de fichiers de Parquet). Nous exécutons Spark sur Mesos et S3 qui était un peu délicat à configurer mais fonctionne vraiment bien une fois fait (vous pouvez lire un résumé de ce qu'il fallait pour bien le configurer ici ).
Spark est un moteur de calcul distribué en mémoire.
Hadoop est un cadre pour le stockage distribué ( HDFS ) et le traitement distribué ( fils ).
Étincelle peut fonctionner avec ou sans composants Hadoop (HDFS/FILS)
distribué Stockage:
étant donné que Spark n'a pas son propre système de stockage distribué, il doit dépendre de l'un de ces systèmes de stockage pour le calcul distribué.
S3 – travaux par lots Non urgents. S3 correspond à des cas d'utilisation très spécifiques lorsque la localisation des données n'est pas critique.
Cassandra - parfait pour l'analyse de données en streaming et un surmenage pour des jobs batch.
HDFS – grand ajustement pour les travaux par lots sans compromis sur la localisation des données.
traitement distribué:
vous pouvez lancer Spark dans trois modes différents: Standalone, fils et Mesos
regardez la question SE ci-dessous pour une explication détaillée sur les deux stockage distribué et traitement distribué.
par défaut , Spark n'a pas de mécanisme de stockage.
pour stocker des données, il a besoin d'un système de fichiers rapide et évolutif. Vous pouvez utiliser S3 ou HDFS ou tout autre système de fichiers. Hadoop est une option économique en raison de son faible coût.
en outre, si vous utilisez Tachyon, il augmentera les performances avec Hadoop. Il est fortement recommandé Hadoop pour Apache spark traitement.
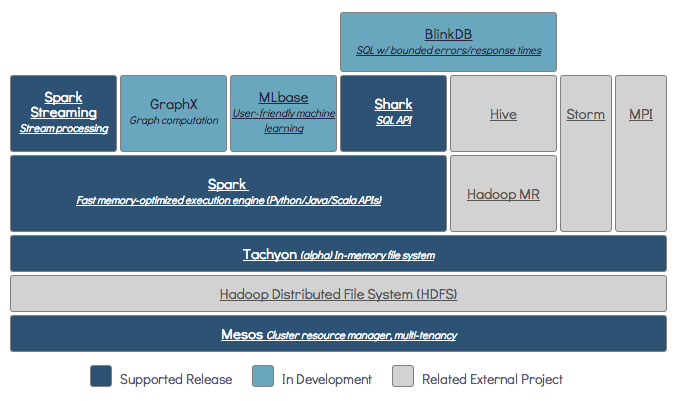
Oui, spark peut fonctionner sans hadoop. Toutes les fonctionnalités du noyau spark continueront à fonctionner, mais vous manquerez des choses comme la distribution facile de tous vos fichiers (code ainsi que des données) à tous les noeuds du cluster via hdfs, etc.
Oui, vous pouvez installer l'Étincelle sans Hadoop. Que serait un peu délicat Vous pouvez utiliser arnon link pour utiliser parquet pour configurer sur S3 comme stockage de données. http://arnon.me/2015/08/spark-parquet-s3/
Spark est seulement faire le traitement et il utilise la mémoire dynamique pour effectuer la tâche, mais pour stocker les données que vous avez besoin d'un certain système de stockage de données. Ici hadoop vient dans le rôle avec Spark, il fournit le stockage pour Spark. Une raison de plus pour utiliser Hadoop avec Spark est ils sont open source et les deux peuvent s'intégrer facilement comme comparer à d'autres systèmes de stockage de données. Pour un autre stockage comme S3, vous devriez être difficile à configurer comme mention dans le lien ci-dessus.
mais Hadoop a aussi son unité de traitement appelée Mapreduce.
vous voulez savoir la différence dans les deux?
vérifier cet article: https://www.dezyre.com/article/hadoop-mapreduce-vs-apache-spark-who-wins-the-battle/83
je pense que cet article vous aidera à comprendre
-
ce que,
-
quand utiliser et
-
comment utiliser !!!
comme dans la documentation Spark, Spark peut fonctionner sans Hadoop.
vous pouvez l'exécuter en mode autonome sans aucun gestionnaire de ressources.
mais si vous voulez exécuter dans la configuration multi-noeuds, vous avez besoin d'un gestionnaire de ressources comme YARN ou Mesos et d'un système de fichiers distribués comme HDFS,S3 etc.
Oui, bien sûr. Spark est un cadre de calcul indépendant. Hadoop est un système de stockage de distribution(HDFS) avec MapReduce cadre de calcul. Spark peut obtenir des données à partir de HDFS, ainsi que toute autre source de données comme la base de données traditionnelle(JDBC), kafka ou même disque local.
Pas de. Il nécessite une installation Hadoop complète pour commencer à travailler - https://issues.apache.org/jira/browse/SPARK-10944