C++11 a introduit un modèle de mémoire standardisé. Qu’est-ce que cela signifie? Et comment cela va-t-il affecter la programmation C++?
C++11 a introduit un modèle de mémoire standardisé, mais qu'est-ce que cela signifie exactement? Et comment cela va-t-il affecter la programmation C++?
Cet article (par Gavin Clarke qui cite Herb Sutter) dit que,
Le modèle de mémoire signifie que le code C++ a maintenant une bibliothèque standardisée à appeler peu importe qui a fait le compilateur et sur quelle plate-forme il fonctionne. Il y a un moyen standard de contrôler comment différents fils parlent à la la mémoire du processeur.
" lorsque vous parlez de fractionnement [code] à travers différents cœurs qui est dans la norme, nous parlons d' le modèle de mémoire. Nous allons optimisez-le sans casser le suivant les hypothèses les gens vont pour faire dans le code," Sutter dit.
Eh bien, je peux mémoriser ceci et des paragraphes similaires disponibles en ligne (comme j'ai eu mon propre modèle de mémoire depuis la naissance: P) et peut même poster comme une réponse à questions posées par d'autres, mais pour être honnête, je ne comprends pas exactement cela.
Donc, ce que je veux essentiellement savoir, c'est que les programmeurs C++ avaient l'habitude de développer des applications multi-threads avant même, alors quelle importance s'il s'agit de threads POSIX, ou de threads Windows, ou de threads C++11? Quels sont les avantages? Je veux comprendre les détails de bas niveau.
J'ai aussi le sentiment que le modèle de mémoire C++11 est en quelque sorte lié au Support multi-threading C++11, Comme je vois souvent ces deux ainsi. Si elle l'est, comment exactement? Pourquoi devraient-ils être liés?
Comme je ne sais pas comment les internes du multi-threading fonctionnent, et ce que signifie le modèle de mémoire en général, Aidez-moi à comprendre ces concepts. :-)
6 réponses
D'abord, vous devez apprendre à penser comme un avocat linguistique.
La spécification C++ ne fait référence à aucun compilateur, système d'exploitation ou CPU particulier. Il fait référence à une machine abstraite {[16] } qui est une généralisation des systèmes réels. Dans le monde de L'avocat de la langue, le travail du programmeur est d'écrire du code pour la machine abstraite; le travail du compilateur est d'actualiser ce code sur une machine concrète. En codant rigidement à la spécification, vous pouvez être certain que votre code compilera et fonctionnera sans modification sur n'importe quel système avec un compilateur C++ Conforme, que ce soit aujourd'hui ou dans 50 ans.
La machine abstraite dans la spécification C++98 / C++03 est fondamentalement mono-thread. Il n'est donc pas possible d'écrire du code C++ multi-thread qui est "entièrement portable" par rapport à la spécification. La spécification ne dit même rien de l'atomicité des charges et des magasins de mémoire ou de l'ordre dans lequel les charges et les magasins pourraient arriver, peu importe les choses comme les Mutex.
Bien sûr, vous pouvez écrire du code multi-thread dans la pratique pour des systèmes concrets particuliers - comme pthreads ou Windows. Mais il n'y a pas destandard moyen d'écrire du code multi-thread pour C++98 / C++03.
La machine abstraite en C++11 est multi-thread par conception. Il a également un modèle de mémoire bien défini ; c'est-à-dire qu'il dit ce que le compilateur peut et ne peut pas faire quand il s'agit d'accéder mémoire.
Prenons l'exemple suivant, où deux threads accèdent simultanément à une paire de variables globales:
Global
int x, y;
Thread 1 Thread 2
x = 17; cout << y << " ";
y = 37; cout << x << endl;
Ce qui pourrait Thread 2 sortie?
Sous C++98 / C++03, Ce N'est même pas un comportement indéfini; la question elle-même est dénuée de sens parce que la norme ne considère rien appelé un "thread".
Sous C++11, le résultat est un comportement indéfini, car les charges et les magasins n'ont pas besoin d'être atomiques en général. Qui peut ne pas sembler comme beaucoup d'amélioration... Et par lui-même, il n'est pas.
Mais avec C++11, Vous pouvez écrire ceci:
Global
atomic<int> x, y;
Thread 1 Thread 2
x.store(17); cout << y.load() << " ";
y.store(37); cout << x.load() << endl;
Maintenant les choses deviennent beaucoup plus intéressantes. Tout d'abord, le comportement ici est défini. Thread 2 peut maintenant imprimer 0 0 (si elle s'exécute avant que le Thread 1), 37 17 (si il court après le Thread 1), ou 0 17 (si il court après le Thread 1 attribue à x, mais avant qu'il assigne à y).
Ce qu'il ne peut pas imprimer est 37 0, car le mode par défaut pour les charges atomiques / magasins en C++11 est d'appliquer cohérence séquentielle . Cela signifie simplement que toutes les charges et les magasins doivent être" comme si " ils se sont produits dans l'ordre dans lequel vous les avez écrits dans chaque thread, tandis que les opérations entre les threads peuvent être entrelacées comme le système le souhaite. Ainsi, le comportement par défaut de l'atomique fournit à la fois atomicité et ordre pour les charges et les magasins.
Maintenant, sur un processeur moderne, assurer une cohérence séquentielle peut être coûteux. En particulier, le compilateur est susceptible d'émettre barrières de mémoire à part entière entre chaque accès ici. Mais si votre algorithme peut tolérer des charges et des magasins hors service; c'est-à-dire s'il nécessite de l'atomicité mais pas de commande; c'est-à-dire s'il peut tolérer 37 0 en sortie de ce programme, alors vous pouvez écrire ceci:
Global
atomic<int> x, y;
Thread 1 Thread 2
x.store(17,memory_order_relaxed); cout << y.load(memory_order_relaxed) << " ";
y.store(37,memory_order_relaxed); cout << x.load(memory_order_relaxed) << endl;
Plus le processeur est moderne, plus il est probable que ce soit plus rapide que l'exemple précédent.
Enfin, si vous avez juste besoin de garder des charges et des magasins particuliers dans l'ordre, vous pouvez écrire:
Global
atomic<int> x, y;
Thread 1 Thread 2
x.store(17,memory_order_release); cout << y.load(memory_order_acquire) << " ";
y.store(37,memory_order_release); cout << x.load(memory_order_acquire) << endl;
Cela nous prend retour aux charges et aux magasins ordonnés - donc 37 0 n'est plus une sortie possible-mais il le fait avec un minimum de frais généraux. (Dans cet exemple trivial, le résultat est le même que la cohérence séquentielle complète; dans un programme plus grand, ce ne serait pas le cas.)
Bien sûr, si les seules sorties que vous voulez voir sont 0 0 ou 37 17, vous pouvez juste envelopper un mutex à travers le code d'origine. Mais si vous avez lu jusqu'ici, je parie que vous savez déjà comment cela fonctionne, et cette réponse est déjà plus longue que moi destiné :-).
Donc, la ligne de fond. Les mutex sont géniaux, et C++11 les standardise. Mais parfois, pour des raisons de performance, vous voulez des primitives de niveau inférieur (par exemple, le modèle de verrouillage classique à double vérification). La nouvelle norme fournit des gadgets de haut niveau comme les mutex et les variables de condition, et il fournit également des gadgets de bas niveau comme les types atomiques et les différentes saveurs de la barrière de mémoire. Maintenant, vous pouvez écrire des routines simultanées sophistiquées et performantes entièrement dans la langue spécifiée par la norme, et vous pouvez être certain que votre code compilera et fonctionnera inchangé sur les systèmes d'aujourd'hui et de demain.
Bien que pour être franc, à moins d'être un expert et de travailler sur un code de bas niveau sérieux, vous devriez probablement vous en tenir aux mutex et aux variables de condition. C'est ce que j'ai l'intention de faire.
Pour en savoir plus sur ce genre de choses, voir cet article de blog.
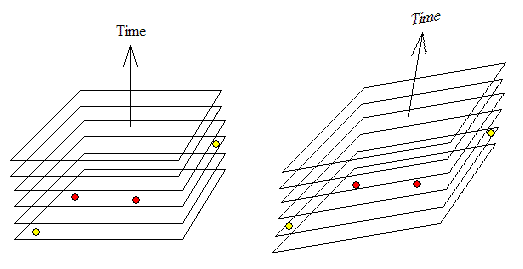
Je vais juste donner l'analogie avec laquelle je comprends les modèles de cohérence de mémoire (ou les modèles de mémoire, pour faire court). Il est inspiré par Leslie Lamport séminal de papier "du Temps, les Horloges, et l'ordre des Événements dans un Système Distribué". L'analogie est appropriée et a une signification fondamentale, mais peut être exagérée pour beaucoup de gens. Cependant, j'espère qu'il fournit une image mentale (une représentation picturale) qui facilite le raisonnement sur les modèles de cohérence de la mémoire.
Affichons le histoires de tous les emplacements de mémoire dans un diagramme espace-temps dans lequel l'axe horizontal représente l'espace d'adressage (c'est-à-dire que chaque emplacement de mémoire est représenté par un point sur cet axe) et l'axe vertical représente le temps (nous verrons qu'en général, il n'y a pas de notion universelle de temps). L'historique des valeurs détenues par chaque emplacement mémoire est donc représenté par une colonne verticale à cette adresse mémoire. Chaque changement de valeur est dû au fait que l'un des threads écrit une nouvelle valeur emplacement. Par un la mémoire d'image, nous allons dire la somme/combinaison de valeurs de tous les emplacements mémoire observables à un moment donné par un thread particulier.
Citant "Une amorce sur la cohérence de la mémoire et la cohérence du Cache"
Le modèle de mémoire intuitif (et le plus restrictif) est la cohérence séquentielle (SC) dans laquelle une exécution multithread devrait ressembler à un entrelacement du séquentiel exécutions de chaque thread constitutif, comme si les threads étaient multiplexés dans le temps sur un processeur monocœur.
Cet ordre de mémoire global peut varier d'une exécution du programme à l'autre et peut ne pas être connu au préalable. La caractéristique de SC est l'ensemble des tranches horizontales dans le diagramme adresse-espace-temps représentant plans de simultanéité (c'est-à-dire des images de mémoire). Sur un plan donné, tous ses événements (ou valeurs de mémoire) sont simultanés. Il y a un notion de Temps absolu , dans lequel tous les threads s'accordent sur les valeurs de mémoire simultanées. Dans SC, à chaque instant, il n'y a qu'une seule image mémoire partagée par tous les threads. C'est-à-dire qu'à chaque instant, tous les processeurs sont d'accord sur l'image mémoire (c'est-à-dire le contenu agrégé de la mémoire). Cela implique non seulement que tous les threads affichent la même séquence de valeurs pour tous les emplacements de mémoire, mais aussi que tous les processeurs observent les mêmes combinaisons de valeurs de toutes variable. C'est la même chose que de dire que toutes les opérations de mémoire (sur tous les emplacements de mémoire) sont observées dans le même ordre total par tous les threads.
Dans les modèles de mémoire détendue, chaque thread découpera l'espace-Adresse-temps à sa manière, la seule restriction étant que les tranches de chaque thread ne doivent pas se croiser car tous les threads doivent s'entendre sur l'historique de chaque emplacement de mémoire individuel (bien sûr, des tranches de threads différents peuvent et vont se croiser). Il n'est pas universel façon de le découper (pas de foliation privilégiée de l'adresse-espace-temps). Les tranches ne doivent pas nécessairement être planes (ou linéaires). Ils peuvent être incurvés et c'est ce qui peut faire lire à un thread des valeurs écrites par un autre thread dans l'ordre dans lequel elles ont été écrites. Les histoires de différents emplacements de mémoire peuvent glisser (ou s'étirer) arbitrairement les unes par rapport aux autres lorsqu'il est vu par un thread particulier. Chaque thread aura un sens différent des événements (ou, de manière équivalente, des valeurs de mémoire) sont simultanées. L'ensemble des événements (ou des valeurs de mémoire) qui sont simultanés à un thread ne sont pas simultanés à un autre. Ainsi, dans un modèle de mémoire détendu, tous les threads observent toujours le même historique (c'est-à-dire une séquence de valeurs) pour chaque emplacement de mémoire. Mais ils peuvent observer différentes images de mémoire (c'est-à-dire des combinaisons de valeurs de tous les emplacements de mémoire). Même si deux emplacements de mémoire différents sont écrits par le même thread dans l'ordre, les deux valeurs nouvellement écrites peuvent être observées dans différents ordre par d'autres threads.
[image de Wikipedia]
Les lecteurs familiers avec la théorie spéciale de la relativité D'Einstein remarqueront ce à quoi je fais allusion. Traduire les mots de Minkowski dans le domaine des modèles de mémoire: l'espace d'adressage et le temps sont des ombres de l'espace-temps d'adressage. Dans ce cas, chaque observateur (c'est-à-dire, thread) projettera des ombres d'événements (c'est-à-dire, des magasins/charges de mémoire) sur sa propre ligne de monde (c'est-à-dire, son axe temporel) et son propre plan de simultanéité (son de l'espace d'adressage de l'axe). Les Threads du modèle de mémoire C++11 correspondent à observateurs qui se déplacent les uns par rapport aux autres en relativité restreinte. La cohérence séquentielle correspond à l'espace-temps Galiléen (c'est-à-dire que tous les observateurs s'accordent sur un ordre absolu d'événements et un sens global de simultanéité).
La ressemblance entre les modèles de mémoire et la relativité spéciale provient du fait que les deux définissent un ensemble d'événements partiellement ordonnés, souvent appelé causal définir. Certains événements (c'est-à-dire les magasins de mémoire) peuvent affecter (mais ne pas être affectés par) d'autres événements. Un thread C++11 (ou observateur en physique) n'est qu'une chaîne (c'est-à-dire un ensemble totalement ordonné) d'événements (par exemple, des charges de mémoire et des magasins à des adresses éventuellement différentes).
En relativité, un certain ordre est restauré à l'image apparemment chaotique des événements partiellement ordonnés, puisque le seul ordre temporel sur lequel tous les observateurs s'accordent est l'ordre entre les événements "timelike" (c'est-à-dire les événements qui sont en principe connectable par toute particule allant plus lentement que la vitesse de la lumière dans le vide). Seuls les événements liés au temps sont invariablement ordonnés. temps en physique, Craig Callender .
Dans le modèle de mémoire C++11, un mécanisme similaire (le modèle de cohérence acquire-release) est utilisé pour les établir relations de causalité locales.
Pour fournir une définition de la cohérence de la mémoire et une motivation pour abandonner SC, je citerai de " A Primer on Cohérence de la mémoire et cohérence du Cache "
Pour une machine à mémoire partagée, le modèle de cohérence de mémoire définit le comportement architectural visible de son système de mémoire. Le critère d'exactitude pour un comportement de partitions de cœur de processeur unique entre " un résultat correct " et " de nombreuses alternatives incorrectes ". En effet, l'architecture du processeur exige que l'exécution d'un thread transforme un État d'entrée donné en une seule sortie bien définie état, même sur un noyau hors service. Cependant, les modèles de cohérence de mémoire partagée concernent les charges et les magasins de plusieurs threads et autorisent généralement de nombreuses exécutions correctes tout en interdisant de nombreuses (plus) exécutions incorrectes. La possibilité de plusieurs exécutions correctes est due à L'ISA permettant à plusieurs threads de s'exécuter simultanément, souvent avec de nombreux entrelacs légaux possibles d'instructions provenant de différents threads.
Détendu ou la faiblesse de la les modèles de cohérence de mémoire sont motivés par le fait que la plupart des ordres de mémoire dans les modèles forts sont inutiles. Si un thread met à jour dix éléments de données, puis un indicateur de synchronisation, les programmeurs ne se soucient généralement pas si les éléments de données sont mis à jour les uns par rapport aux autres, mais seulement que tous les éléments de données sont mis à jour avant que l'indicateur ne soit mis à jour (généralement implémenté à l'aide Les modèles détendus cherchent à capturer cette flexibilité accrue de commande et à préserver uniquement les commandes qui les programmeurs "exigent " pour obtenir à la fois des performances plus élevées et l'exactitude de SC. Par exemple, dans certaines architectures, les tampons D'écriture FIFO sont utilisés par chaque cœur pour contenir les résultats des magasins validés (retirés) avant d'écrire les résultats dans les caches. Cette optimisation améliore les performances, mais viole SC. Le tampon d'écriture cache la latence de l'entretien d'un échec de magasin. Parce que les magasins sont communs, être en mesure d'éviter de caler sur la plupart d'entre eux est un avantage important. Pour un single-core processeur, un tampon d'écriture peut être rendu invisible architecturalement en s'assurant qu'une charge pour adresser a renvoie la valeur du magasin le plus récent À A même si un ou plusieurs magasins à A sont dans le tampon d'écriture. Ceci est généralement fait en contournant la valeur du magasin le plus récent à A à la charge de A, où "le plus récent" est déterminé par l'ordre du programme, ou en bloquant une charge de A si un magasin à A est dans le tampon d'écriture. Lorsque plusieurs cœurs sont utilisés, chacun aura sa propre écriture de contournement tampon. Sans tampons d'écriture, le matériel est SC, mais avec les tampons d'écriture, ce n'est pas le cas, rendant les tampons d'écriture visibles architecturalement dans un processeur multicœur.
Store-la réorganisation du magasin peut se produire si un noyau a un tampon d'écriture non-FIFO qui permet aux magasins de partir dans un ordre différent de l'ordre dans lequel ils sont entrés. Cela peut se produire si le premier magasin manque dans le cache pendant que le second frappe ou si le second magasin peut fusionner avec un magasin précédent (c'est-à-dire avant le premier magasin). Load-la réorganisation de la charge peut également se produire sur des cœurs planifiés dynamiquement qui exécutent des instructions hors de l'ordre du programme. Cela peut se comporter de la même manière que de réorganiser les magasins sur un autre noyau (pouvez-vous trouver un exemple d'entrelacement entre deux threads?). La réorganisation d'un chargement antérieur avec un magasin ultérieur (une réorganisation du magasin de chargement) peut entraîner de nombreux comportements incorrects, tels que le chargement d'une valeur après avoir relâché le verrou qui la protège (si le magasin est l'opération de déverrouillage). Notez que les réorganisations de chargement en magasin peuvent se posent également en raison du contournement local dans le tampon D'écriture FIFO couramment implémenté, même avec un noyau qui exécute toutes les instructions dans l'ordre du programme.
Parce que la cohérence du cache et la cohérence de la mémoire sont parfois confondues, il est instructif d'avoir aussi cette citation:
Contrairement à la cohérence, cohérence du cache n'est ni visible pour le logiciel ni nécessaire. La cohérence cherche à rendre les caches d'un système de mémoire partagée aussi fonctionnellement invisibles que caches dans un système monocœur. Une cohérence correcte garantit qu'un programmeur ne peut pas déterminer si et où un système possède des caches en analysant les résultats des charges et des magasins. C'est parce que la cohérence correcte garantit que les caches n'activent jamais nouveau ou différent fonctionnel comportement (les programmeurs peuvent toujours être en mesure de déduire une structure de cache probable en utilisant calendrier information). Le but principal des protocoles de cohérence de cache est de maintenir le seul auteur-plusieurs lecteurs (SWMR) invariant pour chaque emplacement de mémoire. Une distinction importante entre cohérence et cohérence est que la cohérence est spécifiée sur un base d'emplacement par mémoire, attendu que la cohérence est précisée en ce qui concerne Tous emplacements de mémoire.
En continuant avec notre image mentale, l'invariant SWMR correspond à l'exigence physique qu'il y ait au plus une particule située à n'importe quel endroit mais là peut être un nombre illimité d'observateurs de n'importe quel endroit.
C'est maintenant une question vieille de plusieurs années, mais étant très populaire, il vaut la peine de mentionner une ressource fantastique pour apprendre sur le modèle de mémoire C++11. Je ne vois aucun intérêt à résumer son discours afin de faire encore une autre réponse complète, mais étant donné que c'est le gars qui a réellement écrit la norme, je pense que ça vaut la peine de regarder le discours.
Herb Sutter a une discussion de trois heures sur le modèle de mémoire C++11 intitulé "atomic Weapons", disponible sur le site Channel9 - partie 1 et partie 2. Le discours est assez technique, et couvre les sujets suivants:
- optimisations, courses et modèle de mémoire
- commander-quoi: acquérir et libérer
- Comment commander: Mutex, Atomique et / ou clôtures
- autres Restrictions sur les Compilateurs et le matériel
- code Gen & Performance: x86 / x64, IA64, puissance, BRAS
- Atomiques Détendus
Le discours ne s'étend pas sur L'API, mais plutôt sur le raisonnement, arrière-plan, sous le capot et dans les coulisses (saviez-vous que la sémantique détendue a été ajoutée à la norme uniquement parce que la puissance et le bras ne supportent pas la charge synchronisée efficacement?).
Cela signifie que la norme définit maintenant le multi-threading, et elle définit ce qui se passe dans le contexte de plusieurs threads. Bien sûr, les gens ont utilisé différentes implémentations, mais c'est comme demander pourquoi nous devrions avoir un std::string alors que nous pourrions tous utiliser une classe string roulée à la maison.
Quand vous parlez de threads POSIX ou de threads Windows, alors c'est un peu une illusion car en fait vous parlez de threads x86, car c'est une fonction matérielle à exécuter simultanément. La mémoire C++0x model fait des garanties, que vous soyez sur x86, ou ARM, ou MIPS , ou tout ce que vous pouvez trouver.
Pour les langues ne spécifiant pas de modèle de mémoire, vous écrivez du code pour la langue et le modèle de mémoire spécifié par l'architecture du processeur. Le processeur peut choisir de réorganiser les accès à la mémoire pour des performances. Donc, si votre programme a des courses de données (une course de données est quand il est possible que plusieurs cœurs / hyper-threads accèdent simultanément à la même mémoire), votre programme n'est pas multiplateforme en raison de sa dépendance au modèle de mémoire du processeur. Vous pouvez vous référer pour les manuels de logiciels Intel ou AMD pour savoir comment les processeurs peuvent réorganiser les accès à la mémoire.
Très important, les verrous (et la sémantique de concurrence avec verrouillage) sont généralement implémentés de manière multi-plateforme... Donc, si vous utilisez des verrous standard dans un programme multithread sans courses de données, alors vous n'avez pas à vous soucier des modèles de mémoire multiplateforme .
Fait intéressant, les compilateurs Microsoft pour C++ ont une sémantique acquire / release pour volatile qui est un c++ extension pour faire face à l'absence d'un modèle de mémoire en C++ http://msdn.microsoft.com/en-us/library/12a04hfd (v = vs. 80).aspx . Cependant, étant donné que Windows fonctionne uniquement sur x86 / x64, cela ne dit pas grand-chose (les modèles de mémoire Intel et AMD rendent facile et efficace la mise en œuvre de la sémantique acquire / release dans une langue).
Si vous utilisez des Mutex pour protéger toutes vos données, vous ne devriez vraiment pas vous inquiéter. Les Mutex ont toujours fourni des garanties de commande et de visibilité suffisantes.
Maintenant, si vous avez utilisé l'atomique, ou des algorithmes sans verrou, vous devez penser au modèle de mémoire. Le modèle de mémoire décrit précisément quand les atomiques fournissent des garanties de commande et de visibilité, et fournit des clôtures portables pour des garanties codées à la main.
Auparavant, l'atomique se faisait en utilisant des intrinsèques du compilateur, ou bibliothèque de niveau supérieur. Les clôtures auraient été effectuées en utilisant des instructions spécifiques au processeur (barrières de mémoire).