bash, Linux: définir la différence entre deux fichiers texte
J'ai deux fichiers A-nodes_to_delete et B-nodes_to_keep. Chaque fichier a plusieurs lignes avec des identifiants numériques.
Je veux avoir la liste des id numériques qui sont dans nodes_to_delete, mais PAS dans nodes_to_keep, par exemple alt text http://mathworld.wolfram.com/images/equations/SetDifference/Inline1.gif.
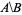{kind=link}
Le faire dans une base de données PostgreSQL est excessivement lent. Une façon soignée de le faire dans bash en utilisant les outils CLI Linux?
UPDATE: cela semblerait être un travail pythonique, mais les fichiers sont vraiment, vraiment grand. J'ai résolu quelques problèmes similaires en utilisant uniq, sort et quelques techniques de théorie des ensembles. C'était environ deux ou trois ordres de grandeur plus rapide que les équivalents de la base de données.
5 réponses
Quelqu'un m'a montré comment faire exactement cela dans sh il y a quelques mois, et je n'ai pas pu le trouver pendant un moment... et en regardant, je suis tombé sur votre question. Ici, il est :
set_union () {
sort $1 $2 | uniq
}
set_difference () {
sort $1 $2 $2 | uniq -u
}
set_symmetric_difference() {
sort $1 $2 | uniq -u
}
Utilisez comm - il comparera deux fichiers triés ligne par ligne
La réponse à la question D'OP en utilisant cet exemple de configuration apparaît ci-dessous. Cette commande renverra des lignes uniques à deleteNodes, pas dans keepNodes
comm -1 -3 <(sort keepNodes) <(sort deleteNodes)Explication: afficher les lignes uniques aux deleteNodes, masquer les autres lignes
Exemple de configuration
Nous allons utiliser keepNodes et deleteNodes. Ils sont utilisés comme entrée non triée.
$ cat > keepNodes <(echo bob; echo amber;)
$ cat > deleteNodes <(echo bob; echo ann;)
Par défaut sans arguments, comm imprime 3 colonnes
unique_to_FILE1
unique_to_FILE2
lines_appear_in_both
Ceci est un exemple barebones de comm sans arguments. Notez les trois colonnes.
$ comm <(sort keepNodes) <(sort deleteNodes)
amber
ann
bob
Suppression de la sortie de colonne
Supprimer la colonne 1, 2 ou 3 avec -N; notez que lorsqu'une colonne est masquée, les espaces se rétrécissent.
$ comm -1 <(sort keepNodes) <(sort deleteNodes)
ann
bob
$ comm -2 <(sort keepNodes) <(sort deleteNodes)
amber
bob
$ comm -3 <(sort keepNodes) <(sort deleteNodes)
amber
ann
$ comm -1 -3 <(sort keepNodes) <(sort deleteNodes)
ann
$ comm -2 -3 <(sort keepNodes) <(sort deleteNodes)
amber
$ comm -1 -2 <(sort keepNodes) <(sort deleteNodes)
bob
Il échouera gracieusement lorsque vous oublierez de trier
comm: file 1 is not in sorted order
comm a été spécifiquement conçu pour ce genre de cas d'utilisation, mais il nécessite une entrée triée.
awk est sans doute un meilleur outil pour cela car il est assez simple de trouver la différence de jeu, ne nécessite pas sort, et offre une flexibilité supplémentaire.
awk 'NR == FNR { a[$0]; next } !($0 in a)' nodes_to_keep nodes_to_delete
Peut-être, par exemple, que vous souhaitez seulement trouver la différence dans les lignes qui représentent des nombres non négatifs:
awk -v r='^[0-9]+$' 'NR == FNR && $0 ~ r {
a[$0]
next
} $0 ~ r && !($0 in a)' nodes_to_keep nodes_to_delete
Peut-être que vous avez besoin d'une meilleure façon de le faire dans postgres, je peux à peu près parier que vous ne trouverez pas un moyen plus rapide de le faire en utilisant des fichiers plats. Vous devriez être capable de faire une simple jointure interne et en supposant que les deux cols id sont indexés, ce qui devrait être très rapide.