Stratégies de sauvegarde pour le seau AWS S3
je suis à la recherche de quelques conseils ou de la meilleure pratique pour sauvegarder S3 bucket.
Le but de sauvegarder les données de S3 est d'empêcher la perte de données à cause de ce qui suit:
- S3 question
- problème où j'ai accidentellement supprimer ces données à partir de S3
Après quelques recherches, je vois les options suivantes:
- Utiliser le contrôle de version http://docs.aws.amazon.com/AmazonS3/latest/dev/Versioning.html
- copier d'un seau S3 à un autre en utilisant AWS SDK
- Sauvegarde sur Amazon Glacier http://aws.amazon.com/en/glacier/
- Sauvegarde sur serveur de production, qui est lui-même sauvegardé
quelle option devrais-je choisir et dans quelle mesure serait-il sécuritaire de stocker des données uniquement sur S3? Je veux entendre vos opinions.
Quelques liens utiles:
- Protection Des Données Documentation
- protection des données FAQ
6 réponses
posté sur mon blog: http://eladnava.com/backing-up-your-amazon-s3-buckets-to-ec2/
synchroniser périodiquement votre seau S3 sur un serveur EC2
cela peut être facilement réalisé en utilisant plusieurs utilitaires de ligne de commande qui permettent de synchroniser un seau S3 distant avec le système de fichiers local.
s3cmd
Au premier abord, s3cmd semblait extrêmement prometteur. Cependant, après l'avoir essayé sur mon énorme seau S3 -- il n'a pas réussi à se mettre à l'échelle, erroring out avec un Segmentation fault. Mais ça marchait bien sur les petits seaux. Comme il ne fonctionnait pas pour les seaux énormes, j'ai entrepris de trouver une alternative.
s4cmd
La plus récente, multi-thread alternative à l' s3cmd. Cela semblait encore plus prometteur, cependant, j'ai remarqué qu'il continuait à télécharger à nouveau des fichiers qui étaient déjà présents sur le système de fichiers local. Ce n'est pas le genre de comportement, j'ai été on attend la commande de synchronisation. Il devrait vérifier si le fichier distant existe déjà localement (la vérification de hash/filesize serait soignée) et le sauter dans la prochaine exécution de synchronisation sur le même répertoire cible. J'ai ouvert un problème (bloomreach/s4cmd / #46) pour signaler ce comportement étrange. En attendant, j'ai décidé de trouver une autre alternative.
awscli
Et puis j'ai trouvé awscli. C'est L'interface de ligne de commande officielle D'Amazon pour interagir avec leurs différents services cloud, S3 inclus.

il fournit une commande de synchronisation utile qui rapidement et facilement télécharge les fichiers bucket distants dans votre système de fichiers local.
$ aws s3 sync s3://your-bucket-name /home/ubuntu/s3/your-bucket-name/
prestations:
- extensible-supporte d'énormes S3 seaux
- Multi-threaded - synchronise les fichiers plus rapidement en utilisant plusieurs threads
- Smart seule synchronise nouveaux ou mis à jour les fichiers
- rapide-grâce à sa nature multi-threadée et à son algorithme de synchronisation intelligente
Suppression Accidentelle
commodément, le sync la commande ne supprimera pas les fichiers dans le dossier de destination (système de fichiers local) s'ils sont absents de la source (seau S3), et vice-versa. C'est parfait pour sauvegarder S3 -- dans le cas où les fichiers sont supprimés du seau, la synchronisation ne les supprimera pas localement. Et dans le cas où vous supprimez un fichier local, il ne sera pas supprimé du seau source non plus.
mise en place awscli sur Ubuntu 14.04 LTS
commençons par installer awscli. Il y a plusieurs façons pour ce faire, cependant, je trouve qu'il est plus facile de l'installer via apt-get.
$ sudo apt-get install awscli
Configuration
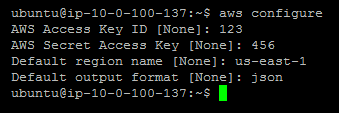
Ensuite, il faut configurer awscli avec notre clé D'accès ID & clé secrète, que vous devez obtenir de IAM, en créant un utilisateur et en attachant le AmazonS3ReadOnlyAccess politique. Cela empêchera également vous ou toute personne qui gagne l'accès à ces justificatifs d'identité de supprimer vos fichiers S3. Assurez-vous d'entrer votre région S3, comme us-east-1.
$ aws configure
Préparation
préparons le répertoire de sauvegarde local S3, de préférence en /home/ubuntu/s3/{BUCKET_NAME}. Assurez-vous de remplacer {BUCKET_NAME} avec votre seau nom.
$ mkdir -p /home/ubuntu/s3/{BUCKET_NAME}
initiale Sync
nous allons aller de l'avant et de synchroniser le seau pour la première fois avec la commande suivante:
$ aws s3 sync s3://{BUCKET_NAME} /home/ubuntu/s3/{BUCKET_NAME}/
en supposant que le seau existe, les identifiants et la région de L'AWS sont corrects, et le dossier de destination est valide,awscli va commencer à télécharger le seau entier dans le système de fichiers local.
selon la taille du seau et de votre connexion Internet, cela peut prendre de quelques secondes à quelques heures. Lorsque cela est fait, nous allons aller de l'avant et mettre up un travail cron automatique pour garder la copie locale du seau à jour.
mise en place une Tâche Cron
Aller de l'avant et créer un sync.sh fichier /home/ubuntu/s3:
$ nano /home/ubuntu/s3/sync.sh
Copier et coller le code suivant dans sync.sh:
#!/bin/sh
# Echo the current date and time
echo '-----------------------------'
date
echo '-----------------------------'
echo ''
# Echo script initialization
echo 'Syncing remote S3 bucket...'
# Actually run the sync command (replace {BUCKET_NAME} with your S3 bucket name)
/usr/bin/aws s3 sync s3://{BUCKET_NAME} /home/ubuntu/s3/{BUCKET_NAME}/
# Echo script completion
echo 'Sync complete'
assurez-vous de remplacer {BUCKET_NAME} avec votre nom de seau S3, deux fois dans le script.
conseil du Pro: Vous devez utiliser
/usr/bin/awslien vers leawsbinaire, commecrontabexécute des commandes dans un environnement shell limité et ne pourra pas trouver l'exécutable tout seul.
Ensuite, assurez-vous de chmod le script pour qu'il puisse être exécuté par crontab.
$ sudo chmod +x /home/ubuntu/s3/sync.sh
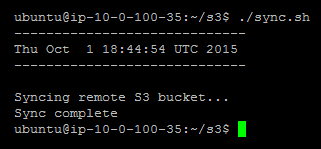
essayons d'exécuter le script pour nous assurer qu'il fonctionne réellement:
$ /home/ubuntu/s3/sync.sh
La sortie devrait être similaire à ceci:
Ensuite, nous allons modifier le courant de l'utilisateur crontab en exécutant la commande suivante:
$ crontab -e
si c'est votre première exécution crontab -e, vous devrez sélectionner un éditeur préféré. Je voudrais vous recommandons de sélectionner nano comme il est plus facile pour les débutants de travailler avec.
Fréquence De Synchronisation
nous devons le dire crontab combien de fois exécuter notre script et où il se trouve sur le système de fichiers local en écrivant une commande. Le format de cette commande est la suivante:
m h dom mon dow command
le la commande suivante configure crontab exécuter sync.sh script toutes les heures (définie via la minute:0 et l'heure:* les paramètres), et elle pipe le script de sortie d'un sync.log le fichier dans notre s3 répertoire:
0 * * * * /home/ubuntu/s3/sync.sh > /home/ubuntu/s3/sync.log
vous devriez ajouter cette ligne au bas du crontab le fichier que vous éditez. Ensuite, allez-y et sauvegardez le fichier sur le disque en appuyant sur Ctrl + W et Entrée. Vous pouvez alors quitter nano en appuyant sur Ctrl + X. crontab va maintenant exécuter la tâche de synchronisation toutes les heures.
conseil du Pro: vous pouvez vérifier que le travail horaire cron est exécuté avec succès en inspectant
/home/ubuntu/s3/sync.log, en vérifiant son contenu pour la date et l'heure d'exécution, et en inspectant les journaux pour voir quels nouveaux fichiers ont été synchronisés.
tout est prêt! Votre seau S3 sera maintenant synchronisé sur votre serveur EC2 toutes les heures automatiquement, et vous devriez être prêt à y aller. Notez que plus de temps, que votre seau S3 devient plus grand, vous pouvez avoir à augmenter la taille de volume de votre serveur EC2 EBS pour accueillir de nouveaux fichiers. Vous pouvez toujours augmenter la taille de votre volume EBS en suivant ce guide.
en tenant compte du lien connexe, qui explique que S3 A 99.9999999% de durabilité, Je rejetterais votre préoccupation #1. Sérieusement.
maintenant, si #2 est un cas d'utilisation valide et un réel souci pour vous, je m'en tiendrais certainement aux options #1 ou #3. Dont l'un d'eux? Cela dépend vraiment de quelques questions:
- avez-vous besoin d'autres fonctionnalités de mise en versions ou est-ce seulement pour éviter les écrasements/suppressions accidentels?
- Est le coût supplémentaire imposé en faisant des versions abordables?
Amazon Glacier is optimized for data that is infrequently accessed and for which retrieval times of several hours are suitable.Est-ce OK pour vous?
A moins que votre utilisation de rangement soit vraiment énorme, je m'en tiendrais au versioning de seau. De cette façon, vous n'aurez pas besoin de code supplémentaire/flux de travail pour sauvegarder des données vers Glacier, vers d'autres seaux, ou même vers tout autre serveur (ce qui est vraiment un mauvais choix IMHO, s'il vous plaît oubliez-le).
on pourrait penser qu'il y aurait un moyen plus facile maintenant de tenir Juste une sorte de sauvegardes incrémentielles sur une région diff.
toutes les suggestions ci-dessus ne sont pas vraiment des solutions simples ou élégantes. Je ne considère pas vraiment glacier comme une option car je pense que c'est plus une solution d'archivage qu'une solution de sauvegarde. Quand je pense à la sauvegarde, je pense à la récupération après sinistre d'un développeur junior effaçant récursivement un seau ou peut-être un exploit ou un bogue dans votre application qui supprime des trucs de s3.
pour moi, la meilleure solution serait un script qui sauvegarde juste un seau dans une autre région, un jour et une semaine pour que si quelque chose de terrible se produit, vous puissiez changer de région. Je n'ai pas une installation comme celle-ci, j'ai regardé dans juste n'ont pas obtenu autour de le faire parce qu'il faudrait un peu d'effort pour le faire ce qui est pourquoi je souhaite qu'il y ait une solution de stock à utiliser.
vous pouvez sauvegarder vos données S3 en utilisant les méthodes suivantes
planifiez le processus de sauvegarde en utilisant AWS dataapipeline ,il peut être fait de 2 façons mentionnées ci-dessous:
A. En utilisant la copyActivity de datapipeline à l'aide de laquelle vous pouvez copier d'un seau s3 à un autre seau s3.
B. En utilisant la ShellActivity de datapipeline et les commandes "S3distcp" pour faire la copie récursive des dossiers récursifs s3 de bucket à un autre (dans parallèle.)
utilisez le versioning à l'intérieur du seau S3 pour maintenir une version différente des données
utilisez glacier pour sauvegarder vos données ( utilisez-le lorsque vous n'avez pas besoin de restaurer la sauvegarde rapide aux seaux d'origine(il faut un certain temps pour récupérer les données de glacier que les données sont stockées en format comprimé) ou lorsque vous voulez économiser un certain coût en évitant d'utiliser un autre S3 bucket fro sauvegarde), cette option peut facilement être mis en utilisant la règle du cycle de vie sur le seau s3 dont vous voulez prendre des renforts.
L'Option 1 peut vous donner plus de sécurité disons dans le cas où vous supprimez accidentellement votre seau original s3 et un autre avantage est que vous pouvez stocker votre sauvegarde dans les dossiers datewise dans un autre seau s3, de cette façon vous savez quelles données vous aviez à une date particulière et pouvez restaurer une date de sauvegarde spécifique . Tout dépend de vous de cas d'utilisation.
Que Diriez-vous d'utiliser le facilement disponible Réplication Entre Régions sur les S3? Voici quelques articles utiles sur la fonction
alors que cette question a été postée il y a quelque temps, j'ai pensé qu'il était important de mentionner MFA deleteaccidentelle suppression des données. L'authentification multifactorielle (AMF) se manifeste dans deux scénarios différents ici -
suppression permanente des versions d'objets-activer la suppression de MFA sur la version du seau.
effacement accidentel du seau lui-même-mettre en place une politique de seau niant supprimer sans authentification MFA.
Couple avec réplication transrégionale et gestion des versions pour réduire le risque de perte de données et d'améliorer les scénarios de récupération.
Voici un blog sur ce sujet avec plus de détails.