Y a-t-il des API pour l'analyse de texte/extraction en Java? [fermé]
je veux savoir s'il y a une API pour faire l'analyse de texte en Java. Quelque chose qui peut extraire tous les mots d'un texte, des mots séparés, des expressions, etc. Quelque chose qui peut informer si un mot est un nombre, date, année, nom, monnaie, etc.
je commence l'analyse de texte maintenant, donc j'ai seulement besoin d'une API pour démarrer. J'ai fait une web-crawler, maintenant j'ai besoin de quelque chose pour analyser les données téléchargées. Besoin de méthodes pour compter le nombre de mots dans une page, mots similaires, type de données et de l'autre les ressources liées à ce texte.
y a-t-il des API pour l'analyse de texte en Java?
EDIT: de Text-mining, je veux minier le texte. Une API pour Java qui fournit ceci.
5 réponses
par exemple - vous pouvez utiliser certaines classes de la bibliothèque standard java.text , ou utiliser StreamTokenizer (vous pouvez le personnaliser selon vos besoins). Mais comme vous le savez - données de texte de sources internet est généralement a de nombreuses erreurs orthographiques et pour une meilleure performance, vous devez utiliser quelque chose comme tokenizer flou - java.le texte et d'autres standart utils a trop de capacités limitées dans un tel contexte .
alors, je vous conseille d'utiliser expressions régulières (java.util.regex) et créer son propre type de tokenizer en fonction de vos besoins.
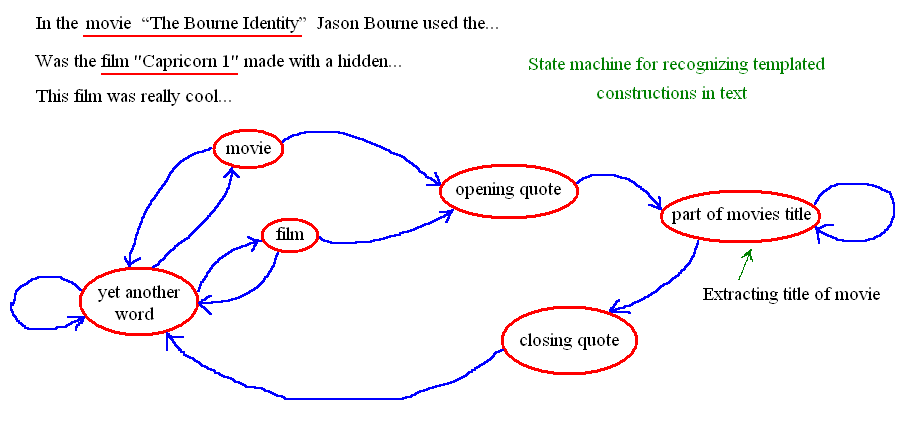
P. S. En fonction de vos besoins - vous pouvez créer un analyseur de machine d'État pour reconnaître les parties de modèles dans les textes bruts. Vous pourriez voir état simple-machine reconnaître sur l'image ci-dessous (vous pouvez construire l'analyseur plus avancé, qui pourrait reconnaître modèles beaucoup plus complexes dans le texte).
on dirait que vous cherchez un nommé reconnaisseur D'entité .
vous avez le choix.
CRFClassifier du Stanford Natural Language Processing Group, est une implémentation Java D'un identificateur D'entité nommé.
GATE (General Architecture for Text Engineering) , une suite libre pour le traitement des langues. Prendre un regardez les captures d'écran à la page pour les développeurs: http://gate.ac.uk/family/developer.html . Il devrait vous donner une brève idée de ce que cela peut faire. Le tutoriel vidéo vous donne un meilleur aperçu de ce que ce logiciel a à offrir.
vous pouvez avoir besoin de personnaliser l'un d'eux pour répondre à vos besoins.
vous avez aussi d'autres options:
- simple d'extraction de texte via le Web services: par exemple Tagthe.net et de Yahoo Terme Extracteur .
- marquage d'une partie de la parole (POS) : extraction d'une partie de la parole (p.ex. verbes, noms) du texte. Voici un post sur SO: Qu'est-ce qu'une bonne bibliothèque Java pour étiqueter des parties de la Parole? .
en termes de formation pour CRFClassifier, vous pourriez trouver un brève explication à leur FAQ :
...les données de formation doivent être dans des colonnes séparées par des onglets, et vous définissez la signification de ces colonnes via une carte. Une colonne devrait être appelé "réponse" et a la TNS classe, et les fonctionnalités existantes savoir sur des noms comme" mot "et"étiquette". Vous définissez le fichier de données, la carte, et quelles fonctionnalités générer via un fichier de propriétés. Il est une documentation considérable des caractéristiques différentes propriété générer dans le Javadoc de NERFeatureFactory, bien que finalement vous je dois aller au code source pour répondre à quelques questions...
vous pouvez également trouver un extrait de code au javadoc de CRFClassifier :
usage courant en ligne de commande
Pour l'exécution d'un modèle appris avec un sérialisé classificateur sur un fichier texte:
java -mx500m edu.stanford.nlp.ie.crf.CRFClassifier -loadClassifier conll.ner.gz -textFile samplesentences.txtlorsqu'on spécifie tous les paramètres d'un fichier de propriétés (train, test, ou runtime):
java -mx1g edu.stanford.nlp.ie.crf.CRFClassifier -prop propFilepour entraîner et tester un modèle NER simple à partir de la ligne de commande:
java -mx1000m edu.stanford.nlp.ie.crf.CRFClassifier -trainFile trainFile -testFile testFile -macro > output
si vous avez affaire à de grandes quantités de données, peut-être que le Lucene D'Apache vous aidera avec ce dont vous avez besoin.
sinon il pourrait être plus facile de créer votre propre classe D'analyseur qui s'appuie fortement sur la classe de modèle standard. De cette façon, vous pouvez contrôler quel texte est considéré comme un mot, limite, numéro, date, etc. Par exemple, est-ce que 20110723 est une date ou un numéro? Vous pourriez avoir besoin d'implémenter un algorithme de parsing à plusieurs passes pour mieux "comprendre" données.
je recommande aussi de regarder LingPipe . Si vous êtes D'accord avec webservices alors cet article a un bon résumé des différents API
je préférerais adapter L'analyse de Lucene et les classes de Stemmer plutôt que de réinventer la roue. Ils ont une très grande majorité des cas couverts. Voir aussi les classes additional et contrib.