Algorithmes de reconnaissance d'entités nommées
Je voudrais utiliser la reconnaissance d'entité nommée (ner) pour trouver des balises adéquates pour les textes dans une base de données.
Je sais qu'il y a un article Wikipedia à ce sujet et beaucoup d'autres pages décrivant NER, je préférerais entendre quelque chose sur ce sujet de votre part:
- Quelles expériences avez-vous faites avec les différents algorithmes?
- Quel algorithme recommanderiez-vous?
- Quel algorithme est le plus facile à implémenter (PHP / Python)?
- Comment les algorithmes fonctionnent? Être formation manuelle nécessaire?
Exemple:
" L'année dernière, j'étais à Londres où J'ai vu Barack Obama."=>Tags: Londres, Barack Obama
J'espère que vous pouvez m'aider. Merci beaucoup à l'avance!
6 réponses
Pour commencer découvrez http://www.nltk.org/ si vous prévoyez de travailler avec python bien que comme je sais que le code n'est pas "force industrielle", mais il vous permettra de commencer.
Consultez la section 7.5 de http://nltk.googlecode.com/svn/trunk/doc/book/ch07.html mais pour comprendre les Algorithmes, vous devrez probablement lire une grande partie du livre.
Vérifiez aussi ceci http://nlp.stanford.edu/software/CRF-NER.shtml . c'est fait avec java,
NER n'est pas un sujet facile et probablement personne ne vous dira "c'est le meilleur algorithme", la plupart d'entre eux ont leurs avantages/inconvénients.
Mon 0,05 d'un dollar.
Santé,
Cela dépend si vous voulez:
pour en savoir plus sur NER : un excellent point de départ est avec NLTK , et le livre associé .
Pour mettre en œuvre la meilleure solution: Ici, vous allez avoir besoin de regarder pour l'état de l'art. Consultez les publications de TREC . Une réunion plus spécialisée est Biocreative (un bon exemple de NER appliqué à un champ étroit).
Pour mettre en œuvre la solution la plus simple: Dans ce cas vous voulez simplement faire un marquage simple, et retirer les mots étiquetés comme noms. Vous pouvez utiliser un tagger de nltk, ou même simplement rechercher chaque mot dans PyWordnet et le marquer avec le wordsense le plus commun.
La plupart des algorithmes nécessitaient une sorte de formation et fonctionnaient mieux lorsqu'ils étaient formés sur un contenu qui représente ce que vous allez lui demander de marquer.
Il existe quelques outils et API.
Il y a un outil construit au-dessus de DBPedia appelé DBPedia Spotlight ( https://github.com/dbpedia-spotlight/dbpedia-spotlight/wiki ). Vous pouvez utiliser leur interface REST ou télécharger et installer votre propre serveur. La grande chose est qu'il mappe les entités à leur présence DBPedia, ce qui signifie que vous pouvez extraire des données liées intéressantes.
AlchemyAPI (www.alchemyapi.com) ont une API qui le fera également via REST, et ils utilisent un freemium modèle.
Je pense que la plupart des techniques reposent sur un peu de PNL pour trouver des entités, puis utilisent une base de données sous-jacente comme Wikipedia, DBPedia, Freebase, etc. pour faire de la désambiguïsation et de la pertinence (par exemple, essayer de décider si un article qui mentionne Apple concerne le fruit ou l'entreprise... nous choisirions la société si l'article comprend d'autres entités qui sont liées à Apple la société).
Vous pouvez essayer le dernier système de liaison d'entité rapide de Yahoo Research-le document a également mis à jour les références aux nouvelles approches de NER en utilisant des intégrations basées sur un réseau neuronal:
Https://research.yahoo.com/publications/8810/lightweight-multilingual-entity-extraction-and-linking
On peut utiliser des réseaux de neurones artificiels pour effectuer une reconnaissance d'entité nommée.
Voici une implémentation d'un réseau LSTM + CRF bidirectionnel dans TensorFlow (python) pour effectuer une reconnaissance d'entité nommée: https://github.com/Franck-Dernoncourt/NeuroNER (fonctionne sous Linux/Mac/Windows).
Il donne des résultats de pointe (ou proches) sur plusieurs ensembles de données de reconnaissance d'entités nommées. Comme Ale le mentionne, chaque algorithme de reconnaissance d'entité nommée a ses propres inconvénients et renversé.
Architecture ANN:
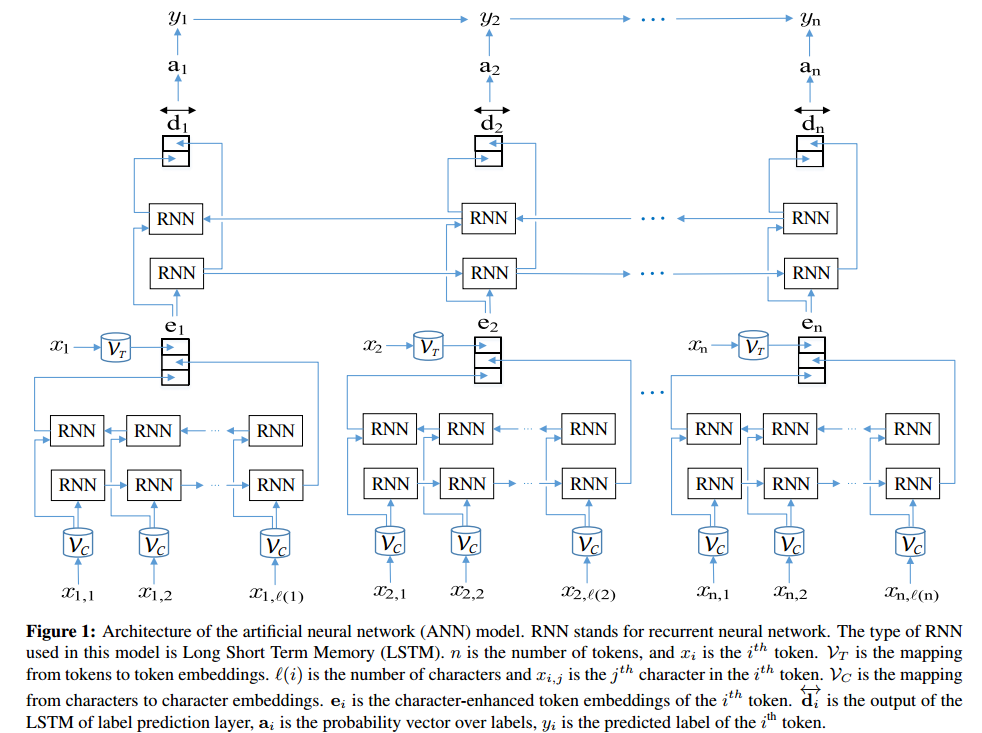
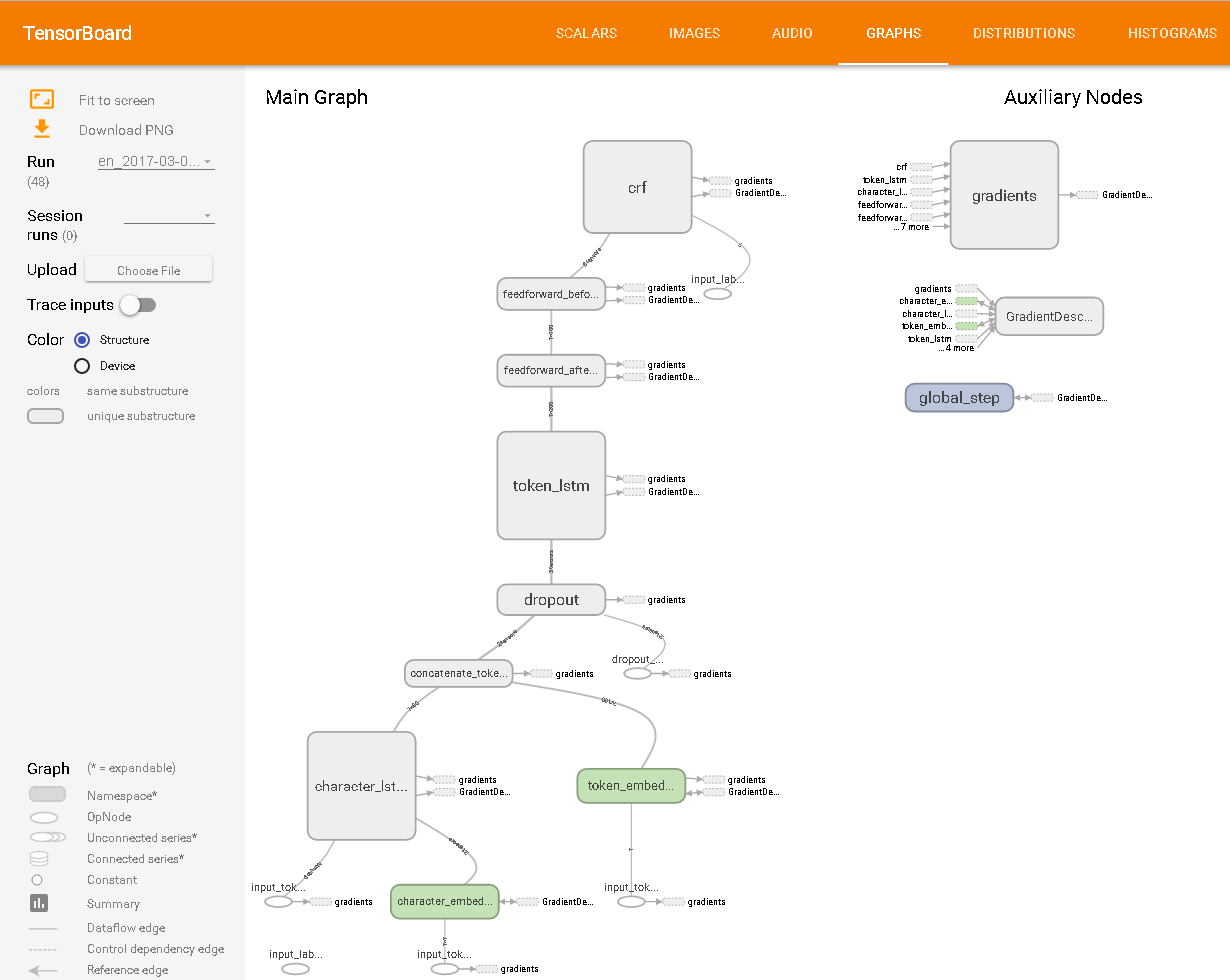
Vu dans TensorBoard:
Je ne sais pas vraiment à propos de NER, mais à en juger par cet exemple, vous pourriez faire un algorithme qui cherchait des lettres majuscules dans les mots ou quelque chose comme ça. Pour cela, je recommanderais regex comme la solution la plus facile à implémenter si vous pensez petit.
Une autre option consiste à comparer les textes avec une base de données, qui correspond à une chaîne pré-identifiée comme étant des balises d'intérêt.
Mes 5 cents.