Algorithme pour trouver l'ancêtre commun le plus bas dans le graphe acyclique dirigé?
Imaginez un graphique acyclique dirigé comme suit, où:
- "A" est la racine (il y a toujours exactement une racine)
- chaque noeud connaît ses parents
- les noms des noeuds sont arbitraires - rien ne peut en être déduit
- nous savons d'une autre source que les noeuds ont été ajoutés à l'arbre dans l'ordre A à G (par ex. ils sont propagés dans un système de contrôle de version)
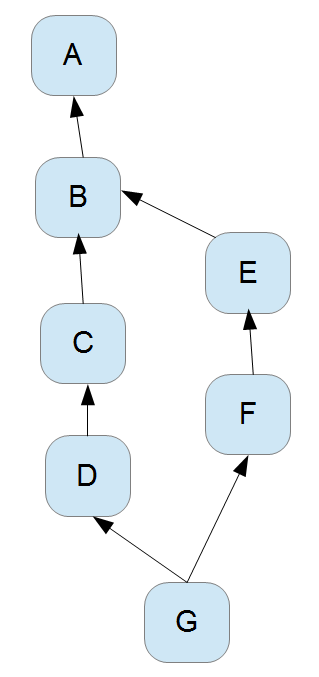
Quel algorithme de pourrais-je utiliser pour déterminer l'ancêtre commun le plus bas (LCA) de deux noeuds arbitraires, par exemple, l'ancêtre commun de:
- B et E est B
- D et F est B
Remarque:
- il n'y a pas nécessairement un seul chemin vers un noeud donné à partir de la racine (par exemple "G" a deux chemins), donc vous ne pouvez pas simplement parcourez les chemins de la racine aux deux noeuds et cherchez le dernier élément d'égalité
- j'ai trouvé des algorithmes D'ACV pour arbres, en particulier les arbres binaires, mais ils ne s'appliquent pas ici parce qu'un noeud peut avoir plusieurs parents (i.e. ce n'est pas un arbre)
10 réponses
le lien de Den Roman semble prometteur, mais cela m'a semblé un peu compliqué, alors j'ai essayé une autre approche. Voici un algorithme simple que j'ai utilisé:
disons que vous voulez calculer LCA (x,y) avec x et o deux nœuds.
Chaque nœud doit avoir une valeur color et count, resp. initialisé blanc et 0.
- Couleur de tous les ancêtres de xbleu (peut être fait à l'aide de BFS)
- Couleur bleu ancêtres de orouge (BFS again)
- Pour chaque rouge noeud dans le graphe, incrémenter ses parents'
countpar un
rouge noeud ayant un count valeur 0 est une solution.
il peut y avoir plus d'une solution, selon votre graphique. Par exemple, considérer ce graphique:
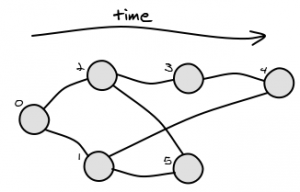
LCA(4,5) les solutions possibles sont 1 et 2.
Remarque: - il encore si vous souhaitez trouver le LCA de 3 nœuds ou plus, vous avez juste besoin d'ajouter une couleur différente pour chacun d'eux.
je cherchais une solution au même problème et j'ai trouvé une solution dans le papier suivant:
http://dx.doi.org/10.1016/j.ipl.2010.02.014
en bref, vous ne cherchez pas l'ancêtre commun le plus bas, mais l'ancêtre commun le plus bas, qu'ils définissent dans cet article.
Juste quelques sauvages de la pensée. Qu'en est-il d'utiliser les deux noeuds d'entrée comme racines, et de faire deux BFS simultanément étape par étape. À une certaine étape, lorsqu'il y a chevauchement dans leurs ensembles noirs (enregistrement des noeuds visités), les arrêts de l'algorithme et les noeuds superposés sont leurs LCA(s). De cette façon, tout autre ancêtre commun aura des distances plus longues que ce que nous avons découvert.
si le graphique a des cycles, alors 'ancêtre' est défini de façon vague. Peut-être voulez-vous dire l'ancêtre sur la sortie de l'arbre D'un DFS ou D'un BFS? Ou peut-être par "ancêtre" vous voulez dire le noeud dans le digraphe qui minimise le nombre de sauts de E et B?
si vous n'êtes pas inquiet de la complexité, alors vous pouvez calculer un A* (ou le chemin le plus court de Dijkstra) à partir de chaque noeud à la fois E et B. Pour les noeuds qui peuvent atteindre les deux E et B, vous pouvez trouver la nœud qui minimise PathLengthToE + PathLengthToB.
modifier: Maintenant que vous avez clarifié certaines choses, je pense que je comprends ce que vous cherchez.
si vous pouvez seulement aller "en haut" de l'arbre, alors je vous suggère d'effectuer un BFS à partir de E et aussi un BFS de B. Chaque noeud de votre graphique aura deux variables associées: sauts de B et de houblon de E. Laissez les deux B et E avoir des copies de la liste des noeuds d'un graphe. Bla liste est triée par le houblon de BEla liste est triée par le houblon de E.
Pour chaque élément B's de la liste, essayez de le trouver dans E'liste. Lieu correspond à une troisième liste, triée par houblon de B + houblon de E. Après que vous avez épuisé B's Liste, votre troisième liste triée devrait contenir L'ACV à sa tête. Cela permet une solution unique, plusieurs solutions (arbitrairement choisies par leurs BFS ordonnant pour B), ou pas de solution.
j'ai aussi besoin exactement de la même chose, pour trouver LCA dans un DAG (courbe acyclique dirigée). Le problème LCA est lié à RMQ (Range Minimum Query Problem).
il est possible de réduire LCA à RMQ et de trouver LCA désiré de deux noeuds arbitraires à partir d'un graphe acyclique dirigé.
j'ai trouvé CE TUTORIEL détail et bon. Je suis également rabotage à mettre en œuvre.
je propose O (V| + |E|) solution de complexité de temps, et je pense que cette approche est correcte sinon s'il vous plaît me corriger.
étant donné le graphe acyclique dirigé, nous devons trouver LCA de deux sommets v et W.
Step1: trouver la distance la plus courte de tous les sommets à partir du sommet de la racine en utilisant bfs http://en.wikipedia.org/wiki/Breadth-first_search with time complexity O (|V | + | E/) and also find the parent of each vertices.
Étape 2: Trouver le les ancêtres communs des deux sommets en utilisant parent jusqu'à ce que nous atteignions le sommet de la racine complexité de temps - 2|v|
Etape 3:LCA sera l'ancêtre commun qui a la plus courte distance.
donc, c'est l'algorithme de complexité temporelle O(|V| + |E|).
s'il vous Plaît, corrigez-moi si je me trompe ou toutes autres suggestions sont les bienvenues.
http://www.gghh.name/dibtp/2014/02/25/how-does-mercurial-select-the-greatest-common-ancestor.html
ce lien décrit comment il est fait dans Mercurial - l'idée de base est de trouver tous les parents pour les noeuds spécifiés, les grouper par distance de la racine, puis faire une recherche sur ces groupes.
Supposons que vous voulez trouver les ancêtres de x et y d'un graphe.
mettre à jour un tableau de vecteurs- parents (stockage des parents de chaque nœud).
tout D'abord faire un bfs(garder les parents de chaque vertex) et trouver tous les ancêtres de x (trouver les parents de x et en utilisant parents, trouver tous les ancêtres de x) et les stocker dans un vecteur. De plus, stockez la profondeur de chaque parent dans le vecteur.
Trouver les ancêtres de y en utilisant la même méthode et les stocker dans un vecteur. Maintenant, vous avez deux vecteurs stockant les ancêtres de x et y respectivement avec leur profondeur.
LCA serait un ancêtre commun avec la plus grande profondeur. La profondeur est définie comme la plus longue distance à partir de la racine(sommet avec in_degree=0). Maintenant, nous pouvons trier les vecteurs en ordre décroissant de leur profondeur et trouver L'ACL. En utilisant cette méthode ,nous pouvons même trouver plusieurs LCA (si y.)
je sais que c'est une vieille question, et d'assez bonne discussion, mais depuis que j'ai eu un problème à résoudre, je suis tombé sur JGraphTAncêtre Commun Le Plus Bas algorithmes, pensé que cela pourrait être de l'aide:
tout le monde. Essayez S'il vous plaît à Java.
static String recentCommonAncestor(String[] commitHashes, String[][] ancestors, String strID, String strID1)
{
HashSet<String> setOfAncestorsLower = new HashSet<String>();
HashSet<String> setOfAncestorsUpper = new HashSet<String>();
String[] arrPair= {strID, strID1};
Arrays.sort(arrPair);
Comparator<String> comp = new Comparator<String>(){
@Override
public int compare(String s1, String s2) {
return s2.compareTo(s1);
}};
int indexUpper = Arrays.binarySearch(commitHashes, arrPair[0], comp);
int indexLower = Arrays.binarySearch(commitHashes, arrPair[1], comp);
setOfAncestorsLower.addAll(Arrays.asList(ancestors[indexLower]));
setOfAncestorsUpper.addAll(Arrays.asList(ancestors[indexUpper]));
HashSet<String>[] sets = new HashSet[] {setOfAncestorsLower, setOfAncestorsUpper};
for (int i = indexLower + 1; i < commitHashes.length; i++)
{
for (int j = 0; j < 2; j++)
{
if (sets[j].contains(commitHashes[i]))
{
if (i > indexUpper)
if(sets[1 - j].contains(commitHashes[i]))
return commitHashes[i];
sets[j].addAll(Arrays.asList(ancestors[i]));
}
}
}
return null;
}
L'idée est très simple. Nous supposons que les commitHashes sont ordonnés en ordre de déclassement. Nous trouvons les index inférieur et supérieur des chaînes(hachures-ne signifie pas). Il est clair que (compte tenu de l'ordre des descendants) l'ancêtre commun ne peut être qu'après l'indice supérieur (valeur inférieure parmi les hachures). Ensuite, nous commençons à énumérer les hashs de commit et construisons la chaîne des chaînes parentales descendantes . Pour cela nous avons deux hashsets sont initialisés par parents de la plus basse et de la plus haute entaille de commettre. setOfAncestorsLower, setOfAncestorsUpper. Si le prochain hash-commit appartient à l'une des chaînes(hashsets)), ensuite, si l'indice courant est supérieur à l'indice de hachage le plus bas, alors s'il est contenu dans un autre ensemble (chaîne), nous retournons le hachage courant comme résultat. Si non, nous ajoutons ses parents (ancêtres[i]) au hashset, qui trace ensemble d'ancêtres de set,, où l'élément courant contenait. C'est le tout, fondamentalement