Regrouper les Segments qui se chevauchent pour mesurer la longueur Effective
j'ai un road_events table:
create table road_events (
event_id number(4,0),
road_id number(4,0),
year number(4,0),
from_meas number(10,2),
to_meas number(10,2),
total_road_length number(10,2)
);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (1,1,2020,25,50,100);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (2,1,2000,25,50,100);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (3,1,1980,0,25,100);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (4,1,1960,75,100,100);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (5,1,1940,1,100,100);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (6,2,2000,10,30,100);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (7,2,1975,30,60,100);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (8,2,1950,50,90,100);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (9,3,2050,40,90,100);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (10,4,2040,0,200,200);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (11,4,2013,0,199,200);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (12,4,2001,0,200,200);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (13,5,1985,50,70,300);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (14,5,1985,10,50,300);
insert into road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) values (15,5,1965,1,301,300);
commit;
select * from road_events;
EVENT_ID ROAD_ID YEAR FROM_MEAS TO_MEAS TOTAL_ROAD_LENGTH
---------- ---------- ---------- ---------- ---------- -----------------
1 1 2020 25 50 100
2 1 2000 25 50 100
3 1 1980 0 25 100
4 1 1960 75 100 100
5 1 1940 1 100 100
6 2 2000 10 30 100
7 2 1975 30 60 100
8 2 1950 50 90 100
9 3 2050 40 90 100
10 4 2040 0 200 200
11 4 2013 0 199 200
12 4 2001 0 200 200
13 5 1985 50 70 300
14 5 1985 10 50 300
15 5 1965 1 301 300
je veux sélectionner les événements qui représentent les travaux les plus récents sur chaque route.
il s'agit d'une opération délicate, car les événements ne concernent souvent qu'une partie de la route . Cela signifie que je ne peux pas simplement sélectionner l'événement le plus récent par route; je dois sélectionnez seulement le plus récent Kilométrage événement qui ne se chevauche pas.
logique Possible (dans l'ordre):
je suis réticent à deviner comment ce problème pourrait être résolu, parce qu'il pourrait finir par blesser plus qu'il n'aide (un peu comme le problème XY ). D'autre part, il pourrait fournir un aperçu de la nature du problème, alors voici:
- , Sélectionnez l'événement le plus récent pour chaque route. Nous appellerons l'événement le plus récent:
event A. - si
event Aest>= total_road_length, alors c'est tout ce dont j'ai besoin. L'algorithme se termine ici. - sinon, obtenez l'événement chronologique suivant (
event B) qui n'a pas les mêmes proportions queevent A. - si les proportions de
event Bchevauchent les étendues deevent A, alors seulement obtenir la partie(s) deevent Bqui ne se chevauchent pas. - répétez les étapes 3 et 4 jusqu'à ce que la longueur totale de l'événement soit
= total_road_length. Ou arrêter quand il n'y a plus d'événements pour cette route.
Question:
je sais que c'est une grosse commande, mais que faudrait-il pour faire ça?
C'est un classique référence linéaire problème. Il serait extrêmement utile si je pouvais faire des opérations de référencement linéaire dans le cadre de requêtes.
le résultat serait:
EVENT_ID ROAD_ID YEAR TOTAL_ROAD_LENGTH EVENT_LENGTH
---------- ---------- ---------- ----------------- ------------
1 1 2020 100 25
3 1 1980 100 25
4 1 1960 100 25
5 1 1940 100 25
6 2 2000 100 20
7 2 1975 100 30
8 2 1950 100 30
9 3 2050 100 50
10 4 2040 200 200
13 5 1985 300 20
14 5 1985 300 40
15 5 1965 300 240
question connexe: choisir où la plage des nombres ne chevauche pas
6 réponses
mon principal SGBD est Teradata, mais cela fonctionnera comme-est dans Oracle, aussi.
WITH all_meas AS
( -- get a distinct list of all from/to points
SELECT road_id, from_meas AS meas
FROM road_events
UNION
SELECT road_id, to_meas
FROM road_events
)
-- select * from all_meas order by 1,2
, all_ranges AS
( -- create from/to ranges
SELECT road_id, meas AS from_meas
,Lead(meas)
Over (PARTITION BY road_id
ORDER BY meas) AS to_meas
FROM all_meas
)
-- SELECT * from all_ranges order by 1,2
, all_event_ranges AS
( -- now match the ranges to the event ranges
SELECT
ar.*
,re.event_id
,re.year
,re.total_road_length
,ar.to_meas - ar.from_meas AS event_length
-- used to filter the latest event as multiple events might cover the same range
,Row_Number()
Over (PARTITION BY ar.road_id, ar.from_meas
ORDER BY year DESC) AS rn
FROM all_ranges ar
JOIN road_events re
ON ar.road_id = re.road_id
AND ar.from_meas < re.to_meas
AND ar.to_meas > re.from_meas
WHERE ar.to_meas IS NOT NULL
)
SELECT event_id, road_id, year, total_road_length, Sum(event_length)
FROM all_event_ranges
WHERE rn = 1 -- latest year only
GROUP BY event_id, road_id, year, total_road_length
ORDER BY road_id, year DESC;
si vous devez retourner la couverture réelle from/to_meas (comme dans votre question avant d'éditer), il pourrait être plus compliqué. La première partie est la même, mais sans agrégation la requête peut retourner des lignes adjacentes avec le même event_id (par exemple pour l'événement 3: 0-1 & 1-25):
SELECT * FROM all_event_ranges
WHERE rn = 1
ORDER BY road_id, from_meas;
si vous voulez fusionner des lignes adjacentes, vous avez besoin de deux étapes supplémentaires (en utilisant un approche standard, signalez la première ligne d'un groupe et calculez un numéro de groupe):
WITH all_meas AS
(
SELECT road_id, from_meas AS meas
FROM road_events
UNION
SELECT road_id, to_meas
FROM road_events
)
-- select * from all_meas order by 1,2
, all_ranges AS
(
SELECT road_id, meas AS from_meas
,Lead(meas)
Over (PARTITION BY road_id
ORDER BY meas) AS to_meas
FROM all_meas
)
-- SELECT * from all_ranges order by 1,2
, all_event_ranges AS
(
SELECT
ar.*
,re.event_id
,re.year
,re.total_road_length
,ar.to_meas - ar.from_meas AS event_length
,Row_Number()
Over (PARTITION BY ar.road_id, ar.from_meas
ORDER BY year DESC) AS rn
FROM all_ranges ar
JOIN road_events re
ON ar.road_id = re.road_id
AND ar.from_meas < re.to_meas
AND ar.to_meas > re.from_meas
WHERE ar.to_meas IS NOT NULL
)
-- SELECT * FROM all_event_ranges WHERE rn = 1 ORDER BY road_id, from_meas
, adjacent_events AS
( -- assign 1 to the 1st row of an event
SELECT t.*
,CASE WHEN Lag(event_id)
Over(PARTITION BY road_id
ORDER BY from_meas) = event_id
THEN 0
ELSE 1
END AS flag
FROM all_event_ranges t
WHERE rn = 1
)
-- SELECT * FROM adjacent_events ORDER BY road_id, from_meas
, grouped_events AS
( -- assign a groupnumber to adjacent rows using a Cumulative Sum over 0/1
SELECT t.*
,Sum(flag)
Over (PARTITION BY road_id
ORDER BY from_meas
ROWS Unbounded Preceding) AS grp
FROM adjacent_events t
)
-- SELECT * FROM grouped_events ORDER BY road_id, from_meas
SELECT event_id, road_id, year, Min(from_meas), Max(to_meas), total_road_length, Sum(event_length)
FROM grouped_events
GROUP BY event_id, road_id, grp, year, total_road_length
ORDER BY 2, Min(from_meas);
Edit:
Ups, je viens de trouver un blog zones de chevauchement avec la priorité faire exactement la même chose avec une syntaxe Oracle simplifiée. En fait, j'ai traduit ma requête à partir d'une autre syntaxe simplifiée dans Teradata en standard / Oracle SQL: -)
il y a une autre façon de calculer ceci, avec des valeurs de et vers:
with
part_begin_point as (
Select distinct road_id, from_meas point
from road_events be
union
Select distinct road_id, to_meas point
from road_events ee
)
, newest_part as (
select e.event_id
, e.road_id
, e.year
, e.total_road_length
, p.point
, LAG(e.event_id) over (partition by p.road_id order by p.point) prev_event
, e.to_meas event_to_meas
from part_begin_point p
join road_events e
on p.road_id = e.road_id
and p.point >= e.from_meas and p.point < e.to_meas
and not exists(
select 1 from road_events ne
where e.road_id = ne.road_id
and p.point >= ne.from_meas and p.point < ne.to_meas
and (e.year < ne.year or e.year = ne.year and e.event_id < ne.event_id))
)
select event_id, road_id, year
, point from_meas
, LEAD(point, 1, event_to_meas) over (partition by road_id order by point) to_meas
, total_road_length
, LEAD(point, 1, event_to_meas) over (partition by road_id order by point) - point EVENT_LENGTH
from newest_part
where 1=1
and event_id <> prev_event or prev_event is null
order by event_id, point
a trop réfléchi à ce sujet aujourd'hui, mais j'ai quelque chose qui ignore le +/- 10 mètres maintenant.
a D'abord créé une fonction qui prend en / de paires comme une chaîne et renvoie la distance couverte par les paires dans la chaîne. Par exemple' 10:20;35:45 ' renvoie 20.
CREATE
OR replace FUNCTION get_distance_range_str (strRangeStr VARCHAR2)
RETURN NUMBER IS intRetNum NUMBER;
BEGIN
--split input string
WITH cte_1
AS (
SELECT regexp_substr(strRangeStr, '[^;]+', 1, LEVEL) AS TO_FROM_STRING
FROM dual connect BY regexp_substr(strRangeStr, '[^;]+', 1, LEVEL) IS NOT NULL
)
--split From/To pairs
,cte_2
AS (
SELECT cte_1.TO_FROM_STRING
,to_number(substr(cte_1.TO_FROM_STRING, 1, instr(cte_1.TO_FROM_STRING, ':') - 1)) AS FROM_MEAS
,to_number(substr(cte_1.TO_FROM_STRING, instr(cte_1.TO_FROM_STRING, ':') + 1, length(cte_1.TO_FROM_STRING) - instr(cte_1.TO_FROM_STRING, ':'))) AS TO_MEAS
FROM cte_1
)
--merge ranges
,cte_merge_ranges
AS (
SELECT s1.FROM_MEAS
,
--t1.TO_MEAS
MIN(t1.TO_MEAS) AS TO_MEAS
FROM cte_2 s1
INNER JOIN cte_2 t1 ON s1.FROM_MEAS <= t1.TO_MEAS
AND NOT EXISTS (
SELECT *
FROM cte_2 t2
WHERE t1.TO_MEAS >= t2.FROM_MEAS
AND t1.TO_MEAS < t2.TO_MEAS
)
WHERE NOT EXISTS (
SELECT *
FROM cte_2 s2
WHERE s1.FROM_MEAS > s2.FROM_MEAS
AND s1.FROM_MEAS <= s2.TO_MEAS
)
GROUP BY s1.FROM_MEAS
)
SELECT sum(TO_MEAS - FROM_MEAS) AS DISTANCE_COVERED
INTO intRetNum
FROM cte_merge_ranges;
RETURN intRetNum;
END;
a ensuite écrit cette requête qui construit une chaîne de caractères pour cette fonction pour la plage antérieure appropriée. Ne pouvait pas utiliser windowing avec list_agg, mais était capable d'atteindre le même avec une sous-requête corrélée.
--use list agg to create list of to/from pairs for rows before current row in the ordering
WITH cte_2
AS (
SELECT T1.*
,(
SELECT LISTAGG(FROM_MEAS || ':' || TO_MEAS || ';') WITHIN
GROUP (
ORDER BY ORDER BY YEAR DESC, EVENT_ID DESC
)
FROM road_events T2
WHERE T1.YEAR || lpad(T1.EVENT_ID, 10,'0') <
T2.YEAR || lpad(T2.EVENT_ID, 10,'0')
AND T1.ROAD_ID = T2.ROAD_ID
GROUP BY road_id
) AS PRIOR_RANGES_STR
FROM road_events T1
)
--get distance for prior range string - distance ignoring current row
--get distance including current row
,cte_3
AS (
SELECT cte_2.*
,coalesce(get_distance_range_str(PRIOR_RANGES_STR), 0) AS DIST_PRIOR
,get_distance_range_str(PRIOR_RANGES_STR || FROM_MEAS || ':' || TO_MEAS || ';') AS DIST_NOW
FROM cte_2 cte_2
)
--distance including current row less distance ignoring current row is distance added to the range this row
,cte_4
AS (
SELECT cte_3.*
,DIST_NOW - DIST_PRIOR AS DIST_ADDED_THIS_ROW
FROM cte_3
)
SELECT *
FROM cte_4
--filter out any rows with distance added as 0
WHERE DIST_ADDED_THIS_ROW > 0
ORDER BY ROAD_ID, YEAR DESC, EVENT_ID DESC
sqlfiddle ici: http://sqlfiddle.com/#!4/81331/36
me semble que les résultats correspondent aux vôtres. J'ai quitté les colonnes supplémentaires dans la requête finale de tenter d'illustrer chaque étape.
fonctionne sur le cas d'essai - pourrait avoir besoin de travail pour gérer toutes les possibilités dans un ensemble de données plus large, mais je pense que ce serait un bon endroit pour commencer et affiner.
crédit pour la fusion de gamme de chevauchement est la première réponse ici: fusionner les intervalles de date de chevauchement
le crédit pour list_agg avec fenêtrage est la première réponse ici: équivalent LISTAGG avec clause de fenêtrage "1519100920
j'ai eu un problème avec vos" événements de route", parce que vous ne décrivez pas ce qui est 1er meas , je pose qu'il est Période entre 0 et 1 Sans 1.
ainsi, vous pouvez compter ceci avec une requête:
with newest_MEAS as (
select ROAD_ID, MEAS.m, max(year) y
from road_events
join (select rownum -1 m
from dual
connect by rownum -1 <= (select max(TOTAL_ROAD_LENGTH) from road_events) ) MEAS
on MEAS.m between FROM_MEAS and TO_MEAS
group by ROAD_ID, MEAS.m )
select re.event_id, nm.ROAD_ID, re.total_road_length, nm.y, count(nm.m) EVENT_LENGTH
from newest_MEAS nm
join road_events re
on nm.ROAD_ID = re.ROAD_ID
and nm.m between re.from_meas and re.to_meas -1
and nm.y = re.year
group by re.event_id, nm.ROAD_ID, re.total_road_length, nm.y
order by event_id
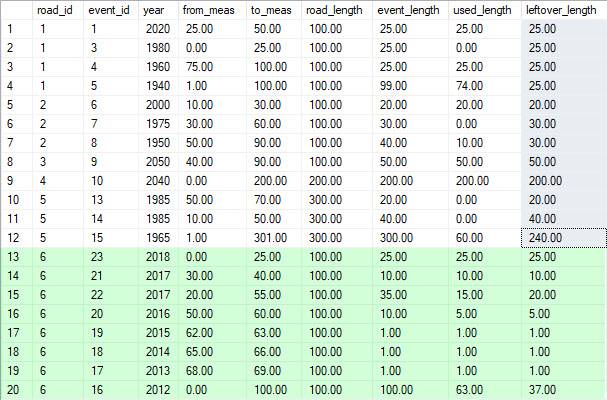
Solution:
SELECT RE.road_id, RE.event_id, RE.year, RE.from_meas, RE.to_meas, RE.road_length, RE.event_length, RE.used_length, RE.leftover_length
FROM
(
SELECT RE.C_road_id[road_id], RE.C_event_id[event_id], RE.C_year[year], RE.C_from_meas[from_meas], RE.C_to_meas[to_meas], RE.C_road_length[road_length],
RE.event_length, RE.used_length, (RE.event_length - (CASE WHEN RE.HasOverlap = 1 THEN RE.used_length ELSE 0 END))[leftover_length]
FROM
(
SELECT RE.C_road_id, RE.C_event_id, RE.C_year, RE.C_from_meas, RE.C_to_meas, RE.C_road_length,
(CASE WHEN MAX(RE.A_event_id) IS NOT NULL THEN 1 ELSE 0 END)[HasOverlap],
(RE.C_to_meas - RE.C_from_meas)[event_length],
SUM( (CASE WHEN RE.O_to_meas <= RE.C_to_meas THEN RE.O_to_meas ELSE RE.C_to_meas END)
- (CASE WHEN RE.O_from_meas >= RE.C_from_meas THEN RE.O_from_meas ELSE RE.C_from_meas END)
)[used_length]--This is the length that is already being counted towards later years.
FROM
(
SELECT RE.C_road_id, RE.C_event_id, RE.C_year, RE.C_from_meas, RE.C_to_meas, RE.C_road_length,
RE.A_event_id, MIN(RE.O_from_meas)[O_from_meas], MAX(RE.O_to_meas)[O_to_meas]
FROM
(
SELECT RE_C.road_id[C_road_id], RE_C.event_id[C_event_id], RE_C.year[C_year], RE_C.from_meas[C_from_meas], RE_C.to_meas[C_to_meas], RE_C.total_road_length[C_road_length],
RE_A.road_id[A_road_id], RE_A.event_id[A_event_id], RE_A.year[A_year], RE_A.from_meas[A_from_meas], RE_A.to_meas[A_to_meas], RE_A.total_road_length[A_road_length],
RE_O.road_id[O_road_id], RE_O.event_id[O_event_id], RE_O.year[O_year], RE_O.from_meas[O_from_meas], RE_O.to_meas[O_to_meas], RE_O.total_road_length[O_road_length],
(ROW_NUMBER() OVER (PARTITION BY RE_C.road_id, RE_C.event_id, RE_O.event_id ORDER BY RE_S.Overlap DESC, RE_A.event_id))[RowNum]--Use to Group Overlaps into Swaths.
FROM road_events as RE_C--Current.
LEFT JOIN road_events as RE_A--After. --Use a Left-Join to capture when there is only 1 Event (or it is the Last-Event in the list).
ON RE_A.road_id = RE_C.road_id
AND RE_A.event_id != RE_C.event_id--Not the same EventID.
AND RE_A.year >= RE_C.year--Occured on or After the Current Event.
AND ( (RE_A.from_meas >= RE_C.from_meas AND RE_A.from_meas <= RE_C.to_meas)--There is Overlap.
OR (RE_A.to_meas >= RE_C.from_meas AND RE_A.to_meas <= RE_C.to_meas)--There is Overlap.
OR (RE_A.to_meas = RE_C.to_meas AND RE_A.from_meas = RE_C.from_meas)--They are Equal.
)
LEFT JOIN road_events as RE_O--Overlapped/Linked.
ON RE_O.road_id = RE_C.road_id
AND RE_O.event_id != RE_C.event_id--Not the same EventID.
AND RE_O.year >= RE_C.year--Occured on or After the Current Event.
AND ( (RE_O.from_meas >= RE_A.from_meas AND RE_O.from_meas <= RE_A.to_meas)--There is Overlap.
OR (RE_O.to_meas >= RE_A.from_meas AND RE_O.to_meas <= RE_A.to_meas)--There is Overlap.
OR (RE_O.to_meas = RE_A.to_meas AND RE_O.from_meas = RE_A.from_meas)--They are Equal.
)
OUTER APPLY
(
SELECT COUNT(*)[Overlap]
FROM road_events as RE_O--Overlapped/Linked.
WHERE RE_O.road_id = RE_C.road_id
AND RE_O.event_id != RE_C.event_id--Not the same EventID.
AND RE_O.year >= RE_C.year--Occured on or After the Current Event.
AND ( (RE_O.from_meas >= RE_A.from_meas AND RE_O.from_meas <= RE_A.to_meas)--There is Overlap.
OR (RE_O.to_meas >= RE_A.from_meas AND RE_O.to_meas <= RE_A.to_meas)--There is Overlap.
OR (RE_O.to_meas = RE_A.to_meas AND RE_O.from_meas = RE_A.from_meas)--They are Equal.
)
) AS RE_S--Swath of Overlaps.
) AS RE
WHERE RE.RowNum = 1--Remove Duplicates and Select those that are in the biggest Swaths.
GROUP BY RE.C_road_id, RE.C_event_id, RE.C_year, RE.C_from_meas, RE.C_to_meas, RE.C_road_length,
RE.A_event_id
) AS RE
GROUP BY RE.C_road_id, RE.C_event_id, RE.C_year, RE.C_from_meas, RE.C_to_meas, RE.C_road_length
) AS RE
) AS RE
WHERE RE.leftover_length > 0--Filter out Events that had their entire Segments overlapped by a Later Event(s).
ORDER BY RE.road_id, RE.year DESC, RE.event_id
SQL Violon:
http://sqlfiddle.com/#!18 / 2880b/1
Ajout De Règles/Hypothèses/Clarifications:
1.) Permettent la possibilité event_id et road_id pourrait être Guid ou créé hors de l'ordre,
donc, ne pas script supposant des valeurs supérieures ou inférieures donner un sens à la relation des enregistrements.
Par Exemple:
Un ID de 1 et et de 2 ne garantit pas que l'ID de 2 est le plus récent (et vice-versa).
C'est ainsi que la solution sera plus générale et moins "hacky".
2.) Filtrer les événements qui ont eu leurs Segments entiers chevauchés par un plus tard Événement (s).
Par Exemple:
Si 2008 avait du travail sur 20-50 et 2009 avait du travail sur 10-60,
puis l'événement de 2008 serait filtré parce que son Segment entier a été ressassé en 2009.
Données D'Essai Supplémentaires:
Pour s'assurer que les solutions ne sont pas adaptées uniquement à L'ensemble de données donné,
J'ai ajouté un road_id de 6 à L'ensemble de données original, afin de frapper un peu plus fringe-cases.
INSERT INTO road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) VALUES (16,6,2012,0,100,100);
INSERT INTO road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) VALUES (17,6,2013,68,69,100);
INSERT INTO road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) VALUES (18,6,2014,65,66,100);
INSERT INTO road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) VALUES (19,6,2015,62,63,100);
INSERT INTO road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) VALUES (20,6,2016,50,60,100);
INSERT INTO road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) VALUES (21,6,2017,30,40,100);
INSERT INTO road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) VALUES (22,6,2017,20,55,100);
INSERT INTO road_events (event_id, road_id, year, from_meas, to_meas, total_road_length) VALUES (23,6,2018,0,25,100);
résultats: ( avec le 8 enregistrements supplémentaires j'ai ajouté dans Vert )
Version De La Base De Données:
Cette Solution est Oracle et SQL-Serveur Agnostic:
Il devrait fonctionner à la fois dans SS2008 + et Oracle 12c +.
Cette question est taggés avec Oracle 12c , mais il n'est pas en ligne violon que je peut l'utiliser sans la signature,
donc je l'ai testé dans SQL-Server - mais la même syntaxe devrait fonctionner dans les deux.
Je compte sur Cross-Apply et Outer-Apply pour la plupart de mes requêtes.
Oracle a introduit ces "Joins" dans 12c:
https://oracle-base.com/articles/12c/lateral-inline-views-cross-apply-and-outer-apply-joins-12cr1
Simplifié et Performant:
Utilisations:
• Aucune Sous-Série Corrélée.
• Pas De Récursivité.
• Pas de CTE.
• En L'Absence De Syndicats.
* Aucune Fonction D'Utilisateur.
index:
J'ai lu dans un de vos commentaires que vous aviez posé des questions sur les index.
J'ajouterais des index D'une colonne pour chacun des principaux champs que vous chercherez et sur lesquels vous grouperez:
road_id , event_id , et year .
Vous pourriez voir si cet index pourrait vous aider (Je ne sais pas comment vous prévoyez d'utiliser les données):
Domaines Clés: road_id , event_id , year
Comprennent: from_meas , to_meas
titre:
Vous pouvez envisager de renommer le titre de cette Question à quelque chose de plus recherchable comme:
" Globale Chevauchement des Segments de Mesurer la Longueur Effective ".
Cela permettrait à la solution d'être plus facile à trouver pour aider les autres avec des problèmes similaires.
Autres Pensées:
Quelque chose comme cela serait utile pour calculer le temps global passé sur quelque chose
avec des horodateurs de démarrage et D'arrêt qui se chevauchent.
cette trouvaille élargit le tableau pour produire une rangée pour chaque mile de chaque route, et prend simplement le MAX année. Nous pouvons juste alors COUNT le nombre de lignes pour produire l'event_length.
il produit le tableau exactement comme vous avez spécifié ci-dessus.
Note: j'ai lancé cette requête contre SQL Server. Vous pourriez utiliser LEAST au lieu de SELECT MIN(event_length) FROM (VALUES...) dans Oracle je pense.
WITH NumberRange(result) AS
(
SELECT 0
UNION ALL
SELECT result + 1
FROM NumberRange
WHERE result < 301 --Max length of any road
),
CurrentRoadEventLength(road_id, [year], event_length) AS
(
SELECT road_id, [year], COUNT(*) AS event_length
FROM (
SELECT re.road_id, n.result, MAX(re.[year]) as [year]
FROM road_events re INNER JOIN NumberRange n
ON ( re.from_meas <= n.result
AND re.to_meas > n.result
)
GROUP BY re.road_id, n.result
) events_per_mile
GROUP BY road_id, [year]
)
SELECT re.event_id, re.road_id, re.[year], re.total_road_length,
(SELECT MIN(event_length) FROM (VALUES (re.to_meas - re.from_meas), (cre.event_length)) AS EventLengths(event_length))
FROM road_events re INNER JOIN CurrentRoadEventLength cre
ON ( re.road_id = cre.road_id
AND re.[year] = cre.[year]
)
ORDER BY re.event_id, re.road_id
OPTION (MAXRECURSION 301) --Max length of any road